This is my learning notes from the book AI for Robotics: Toward Embodied and General Intelligence in the Physical World by by Alishba Imran and Keerthana Gopalakrishnan.
Tổng quan
Tổng quan về sự chuyển dịch của ngành robot từ các ứng dụng công nghiệp hạn chế sang các hệ thống Trí tuệ nhân tạo hiện thân (Embodied AI) có khả năng hoạt động trong thế giới thực đầy biến động.
Sự chuyển dịch sang Robot đa năng (General Purpose Robotics)
Trong quá khứ, robot thường bị giới hạn trong các môi trường công nghiệp có cấu trúc chặt chẽ với các chương trình được “nối cứng” (hard-wired). Tuy nhiên, nhờ sự tiến bộ của Học sâu (Deep Learning), robot hiện đại đang dần trở thành những hệ thống đa năng có khả năng thích nghi với các tình huống chưa từng gặp thông qua việc học từ dữ liệu thay vì dựa trên các quy tắc lập trình sẵn. Sự phổ biến của GPU (Đơn vị xử lý đồ họa) và sự giảm giá thành của pin và máy tính trên bo mạch là những yếu tố then chốt thúc đẩy quá trình này.
Một rào cản lớn trong phát triển robot là Nghịch lý Moravec (Moravec’s Paradox): những nhiệm vụ đòi hỏi tư duy cấp cao ở con người (như phân tích chứng khoán) lại khá dễ đối với AI, nhưng những kỹ năng vận động và cảm giác cơ bản (như đi bộ hoặc cầm một cây bút) lại cực kỳ khó để lập trình cho máy móc
Thành phần của một Hệ thống Robot (A Robot System)
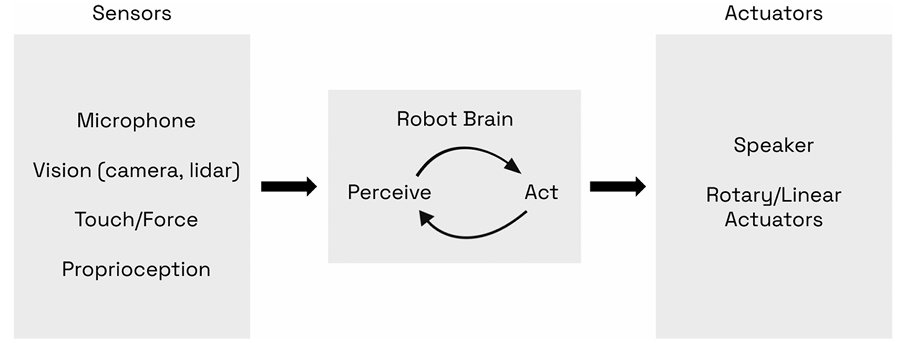
Một robot được định nghĩa là một cỗ máy tương tác, nhận mô hình thế giới và đầu ra là các hành động. Hệ thống này hoạt động thông qua một Vòng lặp nhận thức – hành động (Perception-action loop) liên tục:
- Cảm biến (Sensors): Thu thập dữ liệu từ môi trường (Camera, LiDAR – Cảm biến khoảng cách laser, IMU – Đơn vị đo lường quán tính, Radar).
- Bộ não Robot (Robot Brain): Thường là các bộ vi điều khiển, xử lý dữ liệu đầu vào để tính toán hành động.
- Cơ cấu chấp hành (Actuators): Thực hiện các chuyển động vật lý (động cơ điện, vật liệu mềm trong Soft robotics – Robot mềm)
Phân loại Robot
Robot có thể được phân loại theo hai cách chính:
- Theo lĩnh vực ứng dụng (Vertical): Robot công nghiệp (Industrial), robot dịch vụ (Service), robot y tế (Medical), robot nông nghiệp (Agricultural), robot gia dụng (Domestic).
- Theo hình thức hiện thân (Embodiment): Robot bánh xe (Wheeled), robot chân (Legged), robot bay (Flying), Robot dạng người (Humanoid), robot mềm (Soft robots).
Các khái niệm chính trong thiết kế Robot
- Tay máy Robot (Robotic Manipulators): Gồm một chuỗi các Mắt xích (Links) nối với nhau qua các Khớp (Joints).
- Bậc tự do (Degrees of Freedom – DoF): Phản ánh số lượng các thành phần chuyển động độc lập của robot.
- Cơ cấu tác động cuối (End Effector): Thiết bị ở cuối cánh tay robot dùng để thực hiện nhiệm vụ, phổ biến nhất là Bộ kẹp (Gripper).
- Không gian làm việc (Workspace): Tổng không gian 3D mà robot có thể chiếm giữ; trong đó Không gian với tới (Reachable space) là vùng mà cơ cấu tác động cuối có thể chạm tới.
- Động học (Kinematics): Nghiên cứu chuyển động của các khớp và mắt xích, bao gồm Động học thuận (Forward kinematics) (tính vị trí từ góc khớp) và Động học nghịch (Inverse kinematics) (tính thông số khớp từ vị trí mục tiêu).
Learning Frameworks
Robot học cách thực hiện nhiệm vụ thông qua bốn loại học máy chính:
- Học có giám sát (Supervised learning): Huấn luyện trên dữ liệu đã gắn nhãn.
- Học không giám sát (Unsupervised learning): Khám phá các cấu trúc dữ liệu không nhãn.
- Học giám sát yếu (Weakly supervised learning): Sử dụng nhãn bị nhiễu hoặc không đầy đủ.
- Học tăng cường (Reinforcement learning): Robot tự học thông qua quá trình thử và sai để tối đa hóa phần thưởng.
Ngoài ra, các phương pháp như Học chuyển tiếp (Transfer learning), Học siêu cấp (Meta-learning) và Học đa nhiệm (Multi-task learning) giúp robot trở nên linh hoạt và thông minh hơn.
Robot Perception: Sensors and Image Processing
Bao gồm các loại cảm biến và kỹ thuật xử lý hình ảnh hiện đại để giúp robot hiểu được môi trường xung quanh.
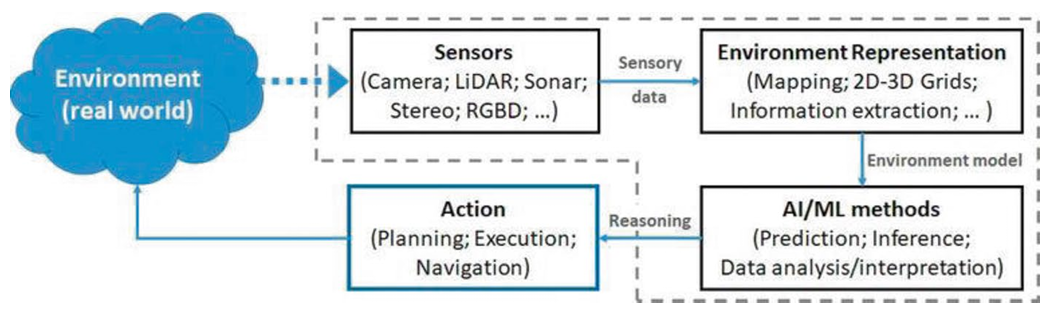
Các loại cảm biến (Sensors)
Cảm biến đóng vai trò là “mắt và tai” của robot, cho phép nó quan sát và ghi lại thế giới vật lý. Các nhóm chính bao gồm:
- Cảm biến thị giác (Vision Sensors/Cameras): Sử dụng cảm biến CMOS hoặc CCD để chuyển đổi ánh sáng thành tín hiệu điện. Các khái niệm quan trọng bao gồm Độ phân giải điểm ảnh (Pixel resolution), Kênh màu (Channels – thường là RGB) và Tốc độ khung hình (Frame rate).
- Camera dựa trên sự kiện (Event-Based Cameras): Chỉ phản hồi với những thay đổi về độ sáng ở cấp độ điểm ảnh, giúp bắt được chuyển động tốc độ cao mà không bị mờ (Motion blur).
- Cảm biến độ sâu (Depth Sensors): Bao gồm Thời gian bay (Time-of-flight – ToF), Ánh sáng cấu trúc (Structured light) và Thị giác lập thể (Stereo vision). Đầu ra thường là Đám mây điểm (Point cloud).
- Cảm biến khoảng cách (Range Sensors): Phổ biến nhất là LiDAR (Light Detection and Ranging) sử dụng xung laser và Cảm biến siêu âm (Ultrasonic sensors) sử dụng sóng âm.
- Đơn vị đo lường quán tính (Inertial Measurement Units – IMUs): Kết hợp giữa Gia tốc kế (Accelerometers), Con quay hồi chuyển (Gyroscopes) và đôi khi là Từ kế (Magnetometers) để theo dõi chuyển động và hướng của robot.
Các bài toán trong nhận thức (Problems in Perception)
Dữ liệu cảm biến được sử dụng để giải quyết các bài toán chính sau:
- Phân loại (Classification): Gán nhãn cho toàn bộ hình ảnh.
- Phân vùng (Segmentation): Bao gồm Phân vùng ngữ nghĩa (Semantic segmentation) (gán nhãn loại đối tượng cho từng điểm ảnh) và Phân vùng thực thể (Instance segmentation) (phân biệt các cá thể khác nhau của cùng một loại đối tượng). Chỉ số đánh giá thường dùng là Giao của hợp (Intersection over Union – IoU).
- Phát hiện đối tượng (Object Detection): Xác định vị trí đối tượng bằng Khung bao (Bounding boxes). Chỉ số đánh giá chính là Độ chính xác trung bình (Average Precision – AP) và mAP (mean Average Precision).
Mạng thần kinh tích chập (Convolutional Neural Networks – CNNs)
CNN là phương pháp phổ biến để xử lý hình ảnh, bao gồm các lớp chính: Lớp tích chập (Convolutional layers) để trích xuất đặc trưng, Hàm kích hoạt phi tuyến (ReLU), Lớp gộp (Pooling layers) để giảm chiều dữ liệu và Lớp kết nối đầy đủ (Fully Connected layers) để phân loại.
Các kiến trúc CNN tiêu biểu: Region-based CNN, ResNet, U-Net, EfficientNet, One-Stage Detectors như YOLO, SSD.
Mạng Transformer cho nhận thức (Transformers for Perception)
Transformer sử dụng Cơ chế tự chú ý (Self-attention) để mô hình hóa các mối liên kết toàn cục giữa các yếu tố thị giác.
Nếu các cảm biến là “giác quan” thu thập thông tin thô, thì CNN và Transformer chính là “vùng vỏ não thị giác” giúp robot biến những con số vô hồn đó thành sự hiểu biết về vật thể, khoảng cách và bối cảnh xung quanh.
Robot Perception: 3D Data and Sensor Fusion
Biểu diễn dữ liệu 3D (3D Data Representation)
Dữ liệu 3D thường thu thập từ LiDAR hoặc Camera độ sâu (Depth cameras) và được biểu diễn qua các dạng chính:
- Đám mây điểm (Point Cloud): Tập hợp các tọa độ (x, y, z) trong không gian.
- Voxel (Điểm thể tích): Các pixel 3D trong một lưới tọa độ, tương tự như pixel của ảnh 2D nhưng có thêm chiều sâu.
- Lưới (Mesh): Biểu diễn vật thể bằng các bề mặt đa giác (thường là hình tam giác).
- Bản đồ độ sâu (Depth Map): Biểu diễn 2.5D trong đó mỗi pixel (x, y) chứa giá trị khoảng cách (z).
Xử lý Đám mây điểm (Processing Point Clouds)
Do đặc tính không có thứ tự và rời rạc của đám mây điểm, các kiến trúc mạng thần kinh chuyên biệt đã được phát triển như: PointNet, PointNet++, PointCNN, Dynamic Graph CNN.
Hợp nhất cảm biến (Sensor Fusion)
Hợp nhất cảm biến (Sensor Fusion) là quá trình kết hợp dữ liệu từ nhiều nguồn (như LiDAR, Radar, Camera) để bù đắp khuyết điểm của nhau. Có hai chiến lược chính:
- Hợp nhất sớm (Early Fusion): Kết hợp dữ liệu thô (ví dụ: chiếu các điểm LiDAR lên ảnh 2D của camera) ngay từ giai đoạn đầu.
- Hợp nhất muộn (Late Fusion): Xử lý độc lập từng loại cảm biến để đưa ra kết quả (như khung bao đối tượng), sau đó mới kết hợp các kết quả này lại với nhau thông qua thuật toán như Bộ lọc Kalman (Kalman Filter)
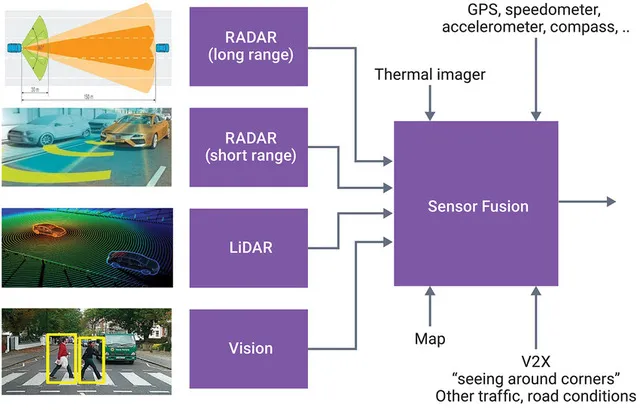
Các phương pháp hợp nhất LiDAR-Camera tiêu biểu: Frustum PointNets, PointPainting & PointAugmenting, DeepFusion, BEVFusion.
Hãy tưởng tượng LiDAR như một người khiếm thị dùng gậy để đo khoảng cách chính xác từng cm, còn Camera như một người mắt sáng có thể phân biệt màu sắc nhưng khó đoán định khoảng cách xa. Sensor Fusion chính là việc kết hợp cả hai: robot vừa biết vật thể trước mặt là một “chiếc xe màu đỏ” (nhờ camera), vừa biết chính xác nó cách xa “5.42 mét” (nhờ LiDAR) để đưa ra quyết định lái xe an toàn.
Mô hình nền tảng (Foundation Models)
Mô hình nền tảng (Foundation Models) trong lĩnh vực robot, đánh dấu sự chuyển dịch từ các hệ thống chuyên biệt sang các hệ thống có khả năng học hỏi và tư duy tổng quát thông qua ngôn ngữ và hình ảnh.
Large Foundation Models
Quá trình phát triển các mô hình này bao gồm hai giai đoạn chính: Huấn luyện trước (Pretraining) trên lượng dữ liệu khổng lồ từ Internet và Sau huấn luyện (Post-training) để tối ưu hóa khả năng làm theo chỉ dẫn. Các kỹ thuật then chốt bao gồm Tinh chỉnh có giám sát (Supervised Fine-tuning – SFT) và Tối ưu hóa sở thích trực tiếp (Direct Preference Optimization – DPO). Ngoài ra, Định luật tỷ lệ (Scaling Laws) giúp các nhà nghiên cứu dự đoán hiệu suất của mô hình dựa trên quy mô tính toán, kích thước dữ liệu và số lượng tham số.
- Robotics Transformers (RT-1, RT-2): Sử dụng kiến trúc Transformer để dự đoán hành động của robot dưới dạng các mã thông báo (Tokens). RT-2 tích hợp khả năng hiểu biết từ Internet (VLA – Vision-Language-Action) giúp robot thực hiện được các nhiệm vụ đòi hỏi lập luận như “nhặt vật thể có màu khác biệt”.
- Mô hình khuếch tán (Diffusion Models): Mô hình khuếch tán (Diffusion Models) như Chính sách khuếch tán (Diffusion Policy) đang trở nên phổ biến vì khả năng xử lý các hành động có độ biến thiên cao và dữ liệu nhiễu tốt hơn các mô hình tự hồi quy truyền thống. Chúng giúp robot thực hiện các động tác đòi hỏi sự khéo léo cao (Dexterous manipulation) bằng cách tinh chỉnh dần dần các hành động từ nhiễu ngẫu nhiên.
- Học từ video (Learning from Video): Robot có thể học các kỹ năng mới bằng cách quan sát con người qua video. Các kỹ thuật như Mô hình hóa thế giới (World Modeling) giúp robot hiểu về vật lý và động lực học của môi trường, từ đó áp dụng vào thực tế thông qua các hệ thống như SWIM hoặc Vid2Robot.
Hãy tưởng tượng một mô hình nền tảng giống như một “bộ não bách khoa toàn thư” đã đọc hết sách trên Internet. Khi được đưa vào thân xác một robot, nó không chỉ biết cách “cầm một chiếc cốc” (điều khiển mức thấp) mà còn hiểu tại sao cần “dọn dẹp cốc bẩn trên bàn” (lập kế hoạch mức cao) dựa trên những gì nó đã học về thói quen của con người.
Simulation
Vai trò của Môi trường mô phỏng (Simulation) trong việc đào tạo robot, giúp giải quyết các thách thức về chi phí, an toàn và khả năng mở rộng dữ liệu trong thế giới thực.
- Lợi ích: Cung cấp môi trường kiểm soát để tạo Dữ liệu tổng hợp (Synthetic data) đa dạng, giúp robot học hỏi mà không gây nguy hiểm cho phần cứng hay con người,. Nó cho phép tăng tốc độ Vòng lặp thử nghiệm (Iteration cycles) và khả năng tái lập các thí nghiệm.
- Thách thức: Rào cản lớn nhất là Khoảng cách từ mô phỏng đến thực tế (Sim2Real gap), nơi các mô hình học trong môi trường ảo có thể không hoạt động chính xác khi triển khai trên robot vật lý do sự khác biệt về động lực học và vật lý.
Các thành phần và Phần mềm mô phỏng phổ biến
Một hệ thống mô phỏng robot thường bao gồm Động cơ vật lý (Physics engine) để xử lý Vật thể rắn (Rigid body) và Vật thể mềm (Soft body), cùng các định dạng chuẩn như URDF (Định dạng mô tả robot thống nhất) để nạp cấu trúc robot.
Mô phỏng trong robot giống như một “phòng tập gym ảo”, nơi robot có thể vấp ngã hàng triệu lần mà không hề hấn gì, từ đó tích lũy đủ kinh nghiệm để bước ra thế giới thực một cách tự tin và an toàn hơn.
Bản đồ hóa (Mapping), Định vị (Localization) và Dẫn đường (Navigation)
Tương tự như việc con người sử dụng mắt để quan sát và não bộ để ghi nhớ bản đồ đường đi, robot sử dụng các cảm biến như “mắt” và các mô hình học sâu như “vùng vỏ não thị giác” để không chỉ nhìn thấy mà còn hiểu được ý nghĩa của từng đồ vật xung quanh nhằm di chuyển một cách thông minh.
- Bản đồ hóa (Mapping) là quá trình tạo ra mô hình môi trường để robot hiểu được không gian xung quanh.
- Định vị (Localization) là việc xác định tư thế (vị trí và hướng) của robot so với bản đồ.
- Dẫn đường (Navigation) bao gồm việc lập kế hoạch đường đi và thực hiện hành động để đạt được mục tiêu. Mô hình Hành động-Ngôn ngữ-Thị giác di động (Mobility VLA): Sử dụng các mô hình như Gemini 1.5 Pro để hiểu chỉ dẫn đa phương thức của người dùng và video hướng dẫn để xác định mục tiêu, sau đó dẫn đường dựa trên Đồ thị topo (Topological graph).
Học tăng cường (Reinforcement Learning – RL)
Học tăng cường hướng tới mục tiêu xây dựng các hệ thống thông minh biết học cách tối ưu hóa hành vi thông qua thử và sai. RL thường được mô hình hóa dưới dạng một Quy trình Quyết định Markov (Markov Decision Process – MDP) bao gồm bốn thành phần chính,:
- S (State space – Không gian trạng thái): Đại diện cho thế giới, ví dụ như tư thế của các vật thể.
- A (Action space – Không gian hành động): Các hành động mà robot có thể thực hiện.
- T (Transition model – Mô hình chuyển cảnh): Xác suất chuyển từ trạng thái này sang trạng thái khác khi thực hiện một hành động cụ thể.
- R (Reward function – Hàm phần thưởng): Giá trị tức thời nhận được sau khi thực hiện hành động.
Một số phương pháp học:
- RL không mô hình (Model-Free RL): Phương pháp này không cố gắng ước tính xác suất chuyển cảnh (T) mà tập trung trực tiếp vào việc học chính sách hoặc giá trị.
- RL dựa trên mô hình (Model-Based RL): Phương pháp này xây dựng một Mô hình thế giới (World model) để dự đoán các trạng thái tương lai, cho phép robot “lập kế hoạch trong tưởng tượng” trước khi thực hiện hành động thực tế. Các mô hình tiêu biểu bao gồm MuZero, PlaNet và Dreamer. Ưu điểm lớn nhất là khả năng giải quyết các nhiệm vụ có tầm nhìn xa (long-horizon tasks) như đánh cờ hoặc giải toán quốc tế.
- Học tăng cường ngoại tuyến (Offline RL): Thay vì học online qua tương tác trực tiếp, robot học từ các tập dữ liệu lớn đã được thu thập sẵn. Ví dụ như Transformer Quyết định (Decision Transformer) coi RL như một bài toán mô hình hóa chuỗi.
- Học tăng cường từ phản hồi của con người (RLHF): Con người xếp hạng các câu trả lời để huấn luyện một mô hình phần thưởng, sau đó dùng PPO để cập nhật LLM.
Nếu Học có giám sát giống như việc học từ sách giáo khoa, thì Học tăng cường giống như việc một đứa trẻ học đi bộ: nó tự khám phá, vấp ngã, nhận được “phần thưởng” là cảm giác đứng vững, và từ đó điều chỉnh các cơ bắp để di chuyển ngày một khéo léo hơn.
Case study minh họa Xe tự lái (Self-Driving Vehicles)
Một hệ thống tự lái nhận đầu vào từ cảm biến và bản đồ, đầu ra là các lệnh Gia tốc (Acceleration) và Góc lái (Steering angle). Hệ thống thường gồm ba module:
- Nhận thức (Perception): Xây dựng mô hình môi trường xung quanh xe.
- Dự đoán (Prediction): Ước tính hành động tương lai của các tác nhân khác.
- Lập kế hoạch và Điều khiển (Planning and Control): Quyết định quỹ đạo di chuyển tối ưu. Ngoài ra, xu hướng Tự lái đầu-cuối (End-to-End Self-Driving – E2E) sử dụng một mạng thần kinh duy nhất để xử lý trực tiếp từ cảm biến sang hành động, dù tính Khả giải (Interpretability) còn hạn chế.
Nhận thức (Perception)
Mục tiêu là tạo ra mô hình môi trường nhận biết được:
- Vật thể tĩnh (Static objects): Đèn giao thông, vạch kẻ làn đường, tòa nhà để hỗ trợ Định vị (Localization) trên bản đồ.
- Vật thể động (Dynamic objects): Xe cộ, người đi bộ, động vật.
- Thông tin ngữ cảnh (Contextual information): Mối quan hệ giữa các vật thể (ví dụ: người đi xe đạp và chiếc xe đạp di chuyển cùng nhau). Quy trình này kết hợp Thị giác máy tính (Computer vision) và Hợp nhất cảm biến (Sensor fusion) để tăng độ chính xác.
Dự đoán (Prediction)
Xe cần dự đoán Ý định (Intent) của các tác nhân khác để đưa ra quyết định an toàn. Các mô hình như ChauffeurNet của Waymo sử dụng mạng RNN và CNN để dự đoán quỹ đạo tương lai dựa trên dữ liệu lịch sử và thông tin bản đồ. Điều này cực kỳ quan trọng tại các Giao lộ (Intersections) hoặc khi nhập làn.
Lập kế hoạch (Planning)
Lập kế hoạch là bài toán tìm quỹ đạo có chi phí thấp nhất, bao gồm:
- Chi phí va chạm (Collision cost): Ưu tiên cao nhất để tránh tai nạn.
- Vi phạm luật giao thông (Traffic rule violation): Như vượt đèn đỏ hoặc chạy quá tốc độ.
- Chi phí khoảng cách và thời gian (Distance and time cost): Tối ưu hóa hành trình. Hầu hết các xe hiện nay dùng Bộ lập kế hoạch dựa trên tìm kiếm (Search-based planners) như thuật toán A* để tìm đường đi trong đồ thị các đoạn làn đường.
An toàn (Safety)
Vì hoạt động trong môi trường có con người, an toàn là yếu tố tiên quyết. Các cân nhắc bao gồm:
- Độ tin cậy của cảm biến (Sensor reliability): Sử dụng đa dạng loại cảm biến để bù đắp điểm yếu của nhau.
- Tính bền vững của thuật toán (Algorithmic robustness): Thử nghiệm kỹ lưỡng trong mô phỏng và thực tế.
- Cơ chế dự phòng (Fail-safe mechanisms): Đảm bảo xe dừng lại an toàn khi có lỗi hệ thống xảy ra.
- An toàn AI (AI Safety): Đảm bảo hệ thống ML minh bạch, không phân biệt đối xử và được bảo mật khỏi các cuộc tấn công mạng.
Data-Driven Robotics
Dữ liệu là “huyết mạch” của robot hiện đại. Các thành phần then chốt bao gồm:
- Thu thập và Lưu trữ (Data Collection and Storage): Đồng bộ hóa dữ liệu cảm biến thành các bộ (trạng thái, hành động, phần thưởng).
- Gán nhãn dữ liệu (Data Labeling): Sử dụng con người để xác định mức độ thành công của một nhiệm vụ hoặc trả lời các câu hỏi thị giác (VQA) để huấn luyện khả năng lập luận cho robot.
- Xử lý dữ liệu (Data Processing): Bao gồm kỹ thuật Gán nhãn lại (Hindsight relabeling) để học từ cả những thất bại trong quá khứ.
- Thuật toán (Algorithms): Cả Học bắt chước (Imitation Learning) và Học tăng cường (Reinforcement Learning) đều cần hạ tầng để phá vỡ dữ liệu robot thành các chuỗi có thể học được.
- Đánh giá hiệu suất (Performance Evaluation): Thực hiện cả Đánh giá ngoại tuyến (Offline evaluation) dựa trên tập dữ liệu thử nghiệm và Đánh giá trong mô phỏng (Evaluation in simulation) để tiết kiệm chi phí.
Vòng xoay dữ liệu Robot (Robot Data Flywheels)
Đây là khái niệm cốt lõi trong thực hành: Sự tích hợp giữa vận hành, hạ tầng và huấn luyện tạo thành một vòng lặp liên tục. Dữ liệu mới giúp cải thiện mô hình, và mô hình tốt hơn lại giúp thu thập dữ liệu chất lượng cao hơn ở những môi trường phức tạp hơn.
Hãy tưởng tượng Vòng xoay dữ liệu (Data Flywheel) giống như một vận động viên chuyên nghiệp. Việc tập luyện hằng ngày là Vận hành (Operations), các thiết bị theo dõi chỉ số cơ thể là Hạ tầng dữ liệu (Data Infrastructure), và huấn luyện viên phân tích chiến thuật là Hạ tầng huấn luyện (Training Infrastructure). Khi cả ba phối hợp nhịp nhàng, vận động viên đó sẽ không ngừng tiến bộ và chinh phục được những kỷ lục mới.
