As we interact with AI today, it is easy to think the AI is actually thinking or aware. We ask a question, and a coherent, often insightful answer appears almost instantly. The experience feels conversational, intentional, sometimes even intelligent.
However, as professionals working in technology and digital transformation, it is critical to look beyond the perceived magic and understand the machinery underneath.
Based on a recent deep dive by Andrej Karpathy, the creation of a Large Language Model, or LLM, is not about birthing a mind. It is about large-scale data engineering, statistical optimization, and a disciplined three-stage training process that loosely mirrors human education. First, reading. Second, imitating. Third, practicing.
This is the reality of how these so-called “token tumblers” are built.
Before LLMs. The Transformer Revolution
Before we talk about Large Language Models, we need to understand the architectural breakthrough that made them possible. The Transformer.
In 2017, Google researchers published a paper titled Attention Is All You Need. This paper fundamentally changed the direction of Natural Language Processing and, eventually, the entire AI industry.
Before Transformers, language models were dominated by recurrent architectures such as RNNs and LSTMs. These models processed text sequentially, one word at a time. This design created two major problems. First, it was slow and hard to parallelize. Second, it struggled to capture long-range dependencies in text, meaning the model often “forgot” important context from earlier parts of a sentence or document.
Self-Attention. The Core Idea
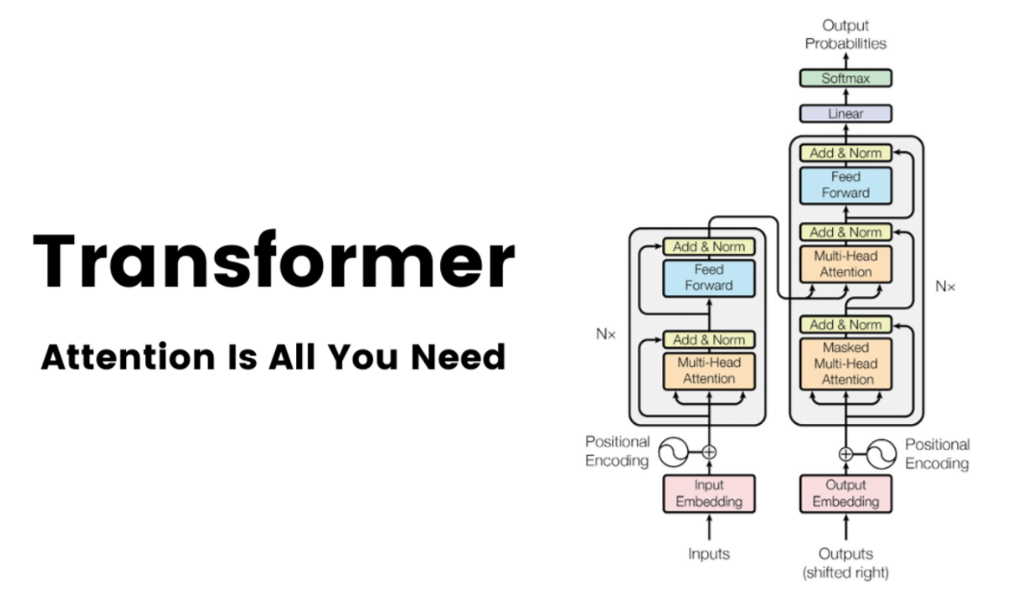
The Transformer introduced a radical idea. Instead of reading text sequentially, the model processes the entire sequence at once and uses a mechanism called self-attention.
Self-attention allows every token in a sentence to directly attend to every other token and decide which ones matter most. In simple terms, each word asks, “Which other words should I pay attention to in order to understand my meaning?”
This solved multiple problems at once. It captured long-range relationships far more effectively. It enabled massive parallel computation on GPUs. And it scaled extremely well with data and model size.
This single architectural shift is the foundation of everything that followed.
From Transformer to Large Language Models
A Transformer on its own is just a neural architecture. What turned it into something powerful was scale.
By stacking many Transformer layers, increasing the number of parameters, and training on enormous amounts of text, researchers discovered an important property. Language ability does not improve linearly. At certain scales, new capabilities suddenly emerge. Reasoning, summarization, translation, and coding all begin to appear without being explicitly programmed.
This is how Large Language Models were born.
GPT. A Decoder-Only Transformer
Models such as GPT (Generative Pre-trained Transformer) are built on a simplified form of the Transformer architecture. Specifically, they use only the decoder part of the original Transformer, optimized for predicting the next token.
By training a decoder-only Transformer on massive datasets and then aligning it through post-training and reinforcement learning, systems like ChatGPT and Google’s Bard emerged.
What feels like conversation or understanding is, at its core, a Transformer using self-attention to compute probabilities over tokens with extreme efficiency and scale.
Why This Matters
Understanding the Transformer clarifies an important truth. Modern LLMs are not mysterious black boxes with human-like cognition. They are large-scale pattern recognition systems enabled by attention, parallelism, and data.
With this foundation in mind, we can now examine how LLMs are actually built. From pre-training, to post-training, to reinforcement learning.
Stage 1. Pre-training. The Diet of Information
This is where the real heavy lifting happens, both computationally and financially. The outcome of this stage is what we call a Base Model.
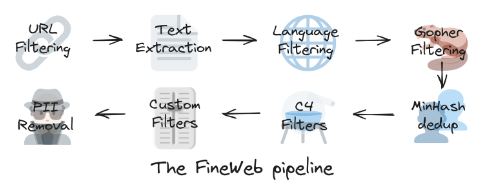
Crawling and Filtering the Internet
Training starts with what is often described as “downloading the internet.” Massive public datasets, such as Common Crawl, are used to collect raw text at scale. But the internet is noisy, biased, repetitive, and sometimes dangerous. A large amount of engineering effort is spent simply cleaning the data.
Key activities include filtering out malicious, low-quality, or adult content. Extracting pure text by removing HTML, CSS, menus, and navigation bars. Applying language and quality filters to ensure the data matches the target language distribution and removing duplicates or personally identifiable information.
This step alone determines much of the model’s eventual behavior and bias profile.
Tokenization. How Models See Text
LLMs do not read words or sentences. They read tokens.
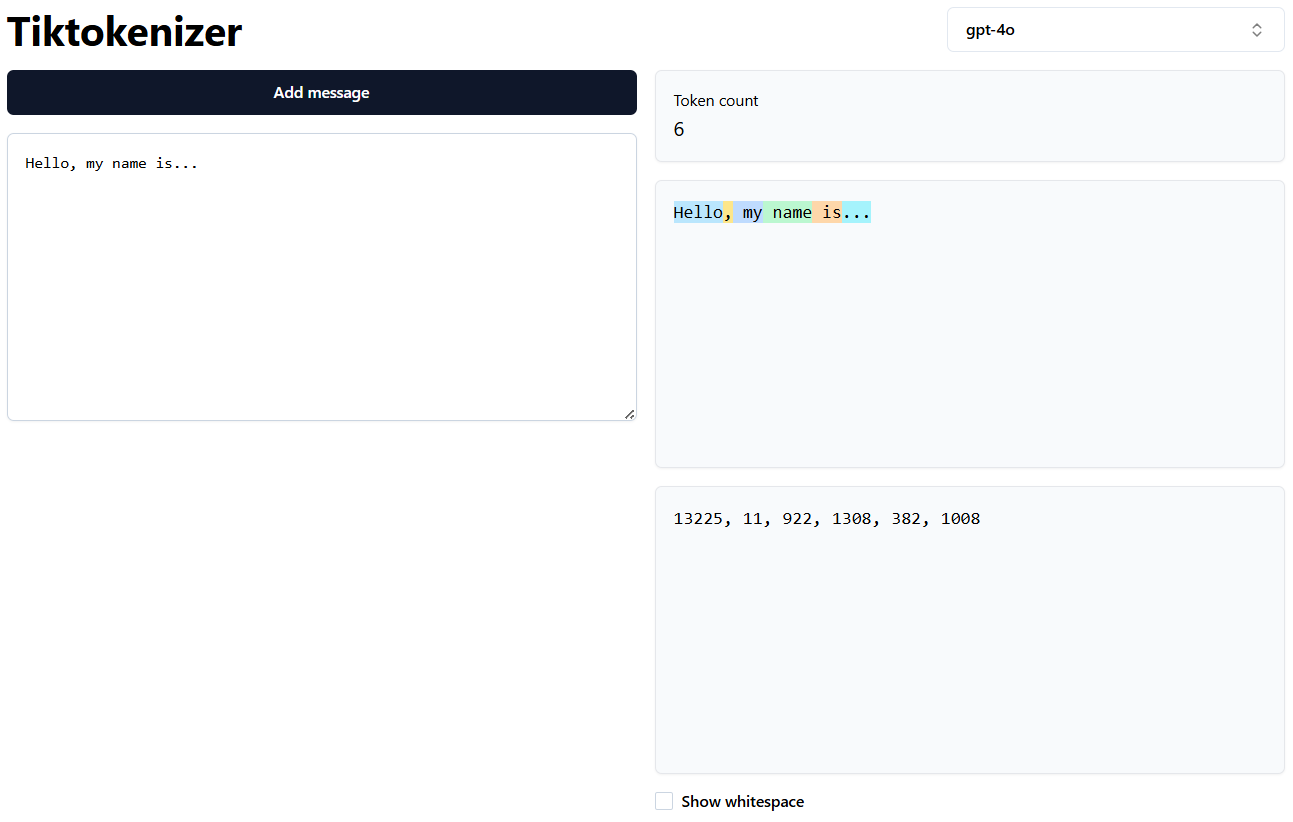
Through tokenization methods such as Byte Pair Encoding, raw text is converted into a sequence of integer IDs. Common words may map to a single token, while rarer or more complex words are broken into multiple tokens.
This explains many surprising limitations of LLMs. When you ask “how many Rs are in strawberry,” the model does not see individual letters. It sees a token representing “strawberry,” so character-level reasoning becomes unreliable.
Training the Neural Network
At this point, the neural network starts with random parameters. It knows nothing.
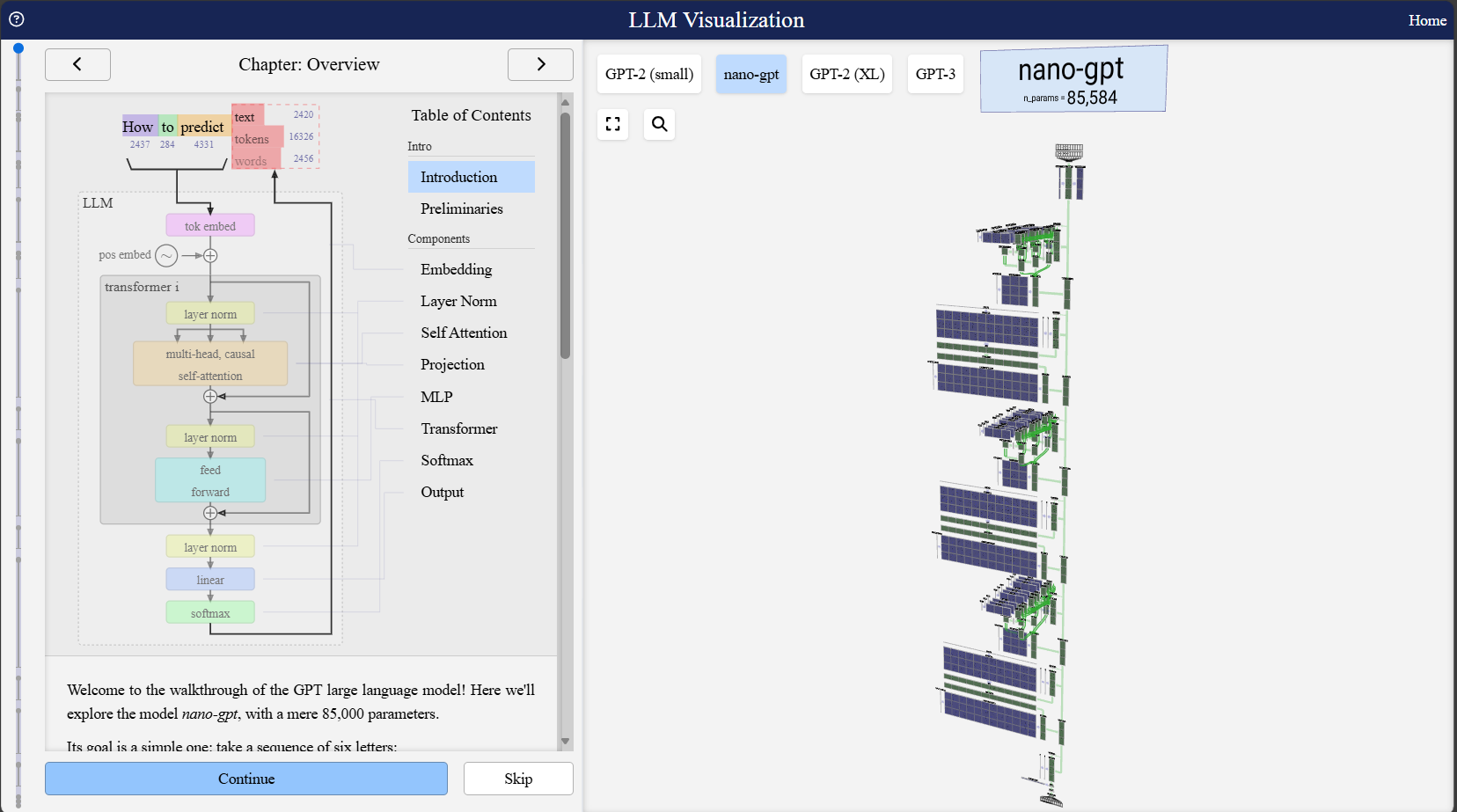
The training objective is simple. Given a sequence of tokens, predict the next token.
The model guesses. The guess is compared with the actual next token from the dataset. If it is wrong, the parameters are adjusted slightly using backpropagation to make the correct token more likely next time.
This process is repeated trillions of times across massive clusters of GPUs.
The result is a Base Model. It is not an assistant. It is best described as an Internet Document Simulator. When prompted, it continues patterns it has seen online. That is why it may answer a question with another question or generate forum-style responses. It has learned structure, not intent.
Stage 2. Post-training. The Assistant School
A Base Model is powerful but chaotic. To make it useful for enterprises and professionals, it must be aligned. This happens through Supervised Fine-Tuning, or SFT.
Programming by Example
Instead of writing rules, we show the model how it should behave.

Human annotators create high-quality prompt and response pairs. For example, a prompt asking for a meeting summary and a response that demonstrates a clear, concise, and professional output.
Thousands or millions of these examples are created, often through specialized vendors and human-in-the-loop platforms.
Imitation Learning
The model is then trained to imitate these ideal responses.
Over time, it stops behaving like a random slice of the internet and starts behaving like a helpful, polite, and safe assistant. It learns to say “I am a helpful AI assistant” not because it understands itself, but because that pattern is statistically reinforced.
This is alignment through imitation, not awareness.
Stage 3. Reinforcement Learning. The Practice Exam
Even after fine-tuning, the model is still primarily copying patterns. To improve reasoning, especially in math, logic, and coding, reinforcement learning is applied.
Verifiable Domains. Math and Code
For problems with objective correctness, the model is given a task but no solution.
It generates multiple attempts. If the code runs successfully or the math answer is correct, that output is rewarded. Incorrect attempts are penalized.
The model begins to learn strategies, such as checking intermediate steps or validating assumptions, that increase the probability of success. This is how newer reasoning-focused models develop stronger problem-solving behavior.

Unverifiable Domains. Creativity and Style
For tasks like writing jokes, stories, or persuasive text, there is no single correct answer.
In these cases, Reinforcement Learning from Human Feedback, or RLHF, is used. Humans rank multiple outputs from best to worst. A separate Reward Model is trained to approximate these preferences.

The LLM then optimizes its outputs to maximize the reward score, effectively learning what humans tend to prefer.
Hallucination and the Illusion of Thinking
Despite all this sophistication, an LLM remains a probabilistic system. It predicts the most likely next token based on context.
When the model lacks sufficient information, it may confidently generate something that sounds plausible but is factually wrong. This is hallucination, not deception.
How We Mitigate This in Practice
Tool usage is one key approach. Instead of guessing a stock price or calculation, the model can be trained to call an external tool such as a search engine, a database, or a Python interpreter. In this setup, the model becomes a reasoning engine rather than a static knowledge store.
Another technique is structured reasoning, often referred to as Chain of Thought. A model has limited compute per token. If asked for an immediate answer to a complex question, it may fail. By encouraging step-by-step reasoning before the final answer, we allow the model to distribute computation over multiple tokens, significantly reducing error rates.
Conclusion. A Jagged but Powerful Tool
A Large Language Model is not a brain. It is closer to a Swiss cheese model of intelligence.
It can solve PhD-level physics problems yet fail at simple numerical comparisons like deciding whether 9.11 is greater than 9.9. These are not contradictions. They are properties of a system optimized for pattern prediction at scale.
For technology leaders, architects, and decision-makers, the responsibility is clear. We must understand these jagged edges. We should not treat LLMs as oracles, but as powerful stochastic tools that require clear instructions, external verification, and thoughtful system design.
Once we understand how they are built and how they truly work, we can move from fascination to effective, responsible adoption.

One thought on “How Large Language Models Are Built and How They Actually Work”