This is my learning note about Retrieval Augmented Generation (RAG) from two sources: RAG-Driven Generative AI, Advanced RAG: Architecture, techniques, applications and use cases and development, and Enhanced Agentic-RAG.
Retrieval Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) as a system architecture designed to address fundamental limitations of Large Language Models (LLMs), specifically hallucination, stale knowledge, and lack of grounding.
Problem Definition
LLMs generate responses based on parametric knowledge, meaning information encoded in model weights during training. They cannot reliably answer questions about:
- Data outside the training cutoff
- Domain-specific or proprietary content
- Rapidly changing information
When required knowledge is missing, the model still produces output, leading to hallucinations or irrelevant responses.
Core RAG Concept
RAG augments LLMs with a retrieval component that fetches relevant external data at query time. The retrieved data is injected into the prompt, allowing the model to generate responses grounded in explicit sources.
At a high level, RAG consists of two main components:
- Retriever: Fetches relevant data from external knowledge sources
- Generator: An LLM that consumes the augmented input and produces output
RAG bridges parametric knowledge (model weights) and non-parametric knowledge (explicit stored data).
RAG Configurations
- Naïve RAG: is the foundational approach to retrieval-augmented generation. It operates on a simple mechanism where the system retrieves relevant chunks of information from a knowledge base using keyword search and basic matching in response to a user query. These retrieved chunks are then used as context for generating a response through a language model.
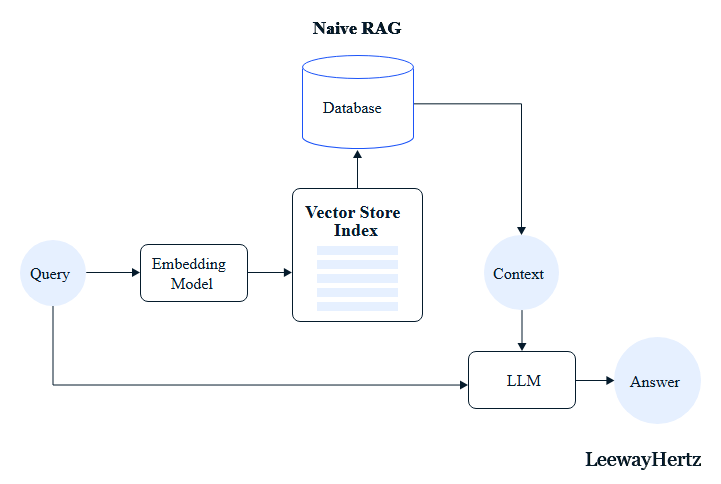
- Advanced RAG: Uses embeddings, vector search, and index-based retrieval. Supports semantic similarity, large datasets, and unstructured data.
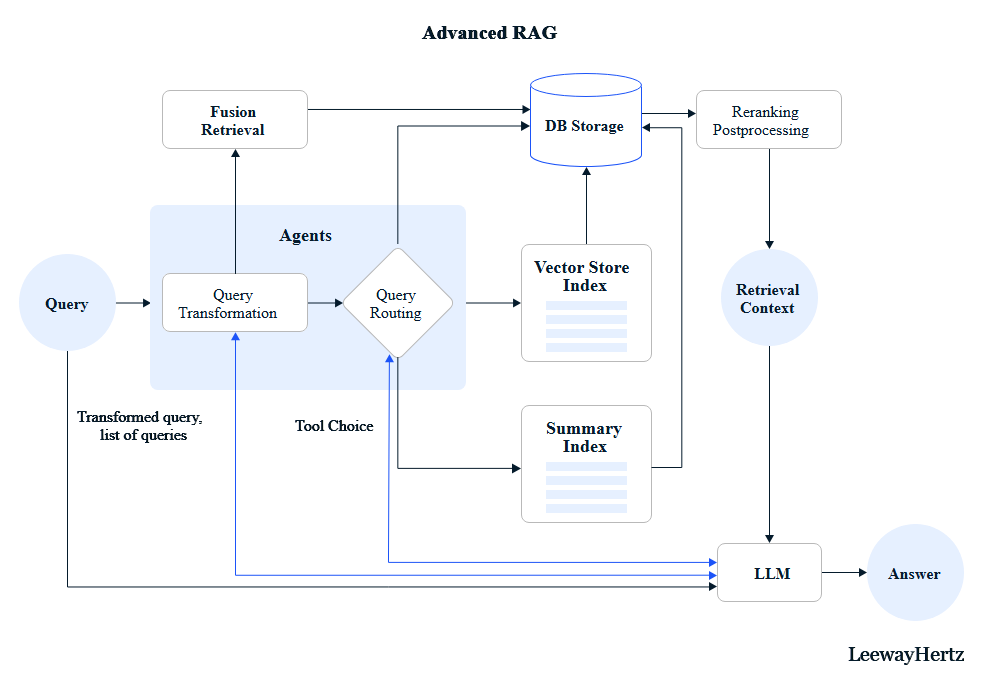
- Modular RAG: Combines multiple retrieval strategies (keyword, vector, index-based, ML-based). Enables flexible selection of retrieval methods per use case.
RAG vs Fine-Tuning
The chapter clarifies that RAG and fine-tuning solve different problems.
- Fine-tuning modifies model weights. Best for static, domain-specific behavior.
- RAG retrieves external data dynamically. Best for frequently changing or auditable knowledge.
The RAG Ecosystem
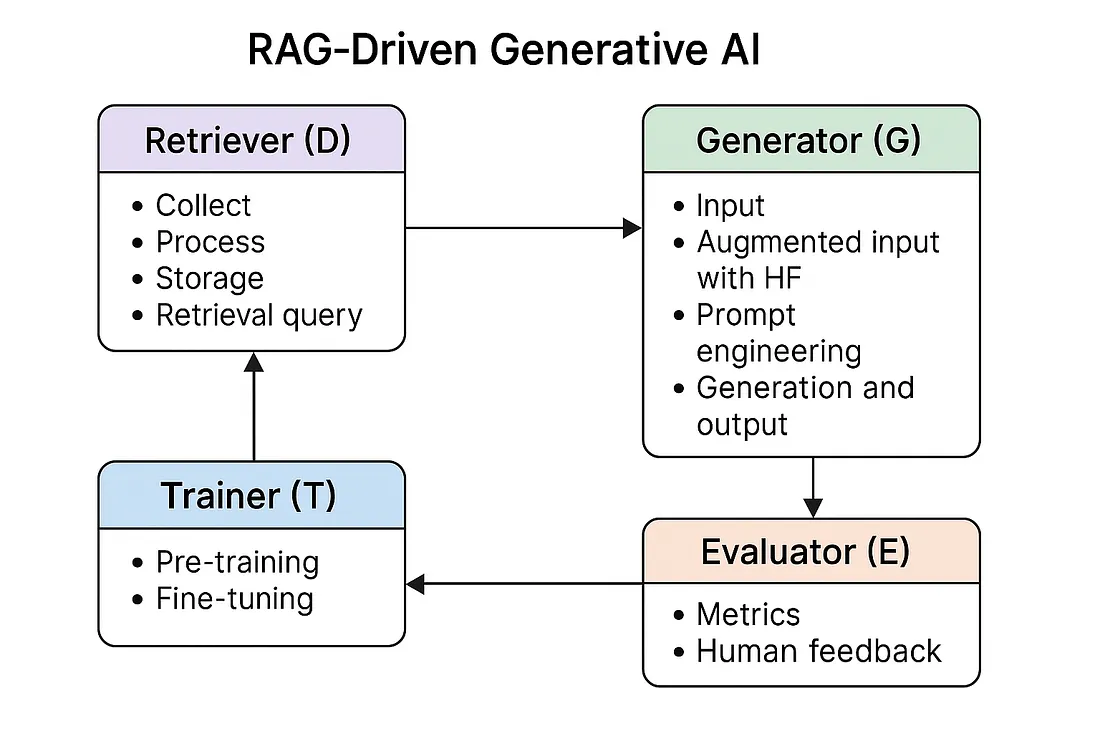
RAG is presented as a multi-component system rather than a single pipeline. Four functional domains are defined:
- Retriever (D): Data collection, processing, storage, and retrieval
- Generator (G): Prompt construction, augmented input, and generation
- Evaluator (E): Metrics, similarity scoring, and human feedback
- Trainer (T): Pre-training and fine-tuning of models
This separation enables modular development, scaling, and governance.
Embeddings and Vector Stores in RAG Systems
RAG systems cannot retrieve raw text directly. All retrievable content must be converted into embedding vectors, numerical representations that encode semantic meaning.
Key steps include:
- Text preprocessing and chunking
- Embedding generation using embedding models (for example OpenAI embeddings)
- Normalization of vectors for similarity comparison
Embeddings enable semantic similarity. Documents with similar meaning are close in vector space even if they share few keywords.
Chunking Strategy
Chunking determines the unit of retrieval. Chunking directly impacts retrieval quality, token usage, and generation cost. Solution trade-offs include:
- Large chunks preserve context but reduce precision
- Small chunks improve precision but risk losing meaning
- Overlap and sliding windows mitigate context loss
Vector Stores as Retrieval Infrastructure
Vector stores such as Activeloop Deep Lake and Pinecone are introduced as core RAG infrastructure components. A vector store provides:
- Persistent storage for embedding vectors
- Similarity search using distance metrics (commonly cosine similarity)
- Indexing for efficient Approximate Nearest Neighbor (ANN) search
- Metadata linkage to original source documents
Index-Based RAG
Direct vector similarity search requires comparing a query embedding against all document embeddings. This approach has linear time complexity and does not scale well as the corpus grows.
Index-based RAG addresses this by precomputing structured representations of documents that allow faster similarity lookup at query time.
Vector Search vs Index-Based Search
The chapter contrasts two approaches.
- Vector search computes similarity dynamically against document vectors.
- Index-based search compares the query against a prebuilt vector index.
Index-based search provides:
- Faster retrieval
- More stable latency
- Better scalability for large datasets
Both approaches can return similar results for small corpora, but indexing becomes critical at scale.
Multimodal Modular RAG. Extending Retrieval Beyond Text
Why Multimodal RAG Is Necessary
Text-only RAG systems are insufficient for domains where meaning is distributed across multiple modalities, such as images, diagrams, sensor data, or video frames.
Multimodal RAG enables:
- Cross-modal retrieval (text query retrieving images, or vice versa)
- Context enrichment across data types
- More accurate grounding for generative outputs
The core idea remains unchanged. Retrieval augments generation. The difference is that retrieval now operates across heterogeneous data.
Multimodal Data Ingestion and Processing
Each modality is processed separately:
- Text is chunked and embedded using text embedding models
- Images are embedded using vision or vision-language models (VLMs)
Despite different embedding models, all outputs are normalized into vectors that can be indexed and retrieved.
Separate Indices, Unified Retrieval
A key architectural decision highlighted is index separation by modality.
- Text embeddings are stored in a text vector index
- Image embeddings are stored in an image vector index
Modular RAG Architecture
Reinforce modular RAG as a structural requirement for multimodal systems.
- Modality-specific retrievers
- A routing mechanism that determines which retrievers to invoke
- A unification step that aggregates retrieved context before generation
Retrieval-Augmented Generation Flow
The end-to-end flow is:
- User query is analyzed
- Relevant retrievers are selected (text, image, or both)
- Retrieved artifacts are converted into a common contextual representation
- Context is injected into the prompt
- The generative model produces a response grounded in multimodal evidence
Adaptive RAG with Expert Human Feedback
Extending standard RAG by integrating human feedback as a first-class signal to improve retrieval quality, ranking, and generation accuracy over time.
Motivation for Adaptive RAG
Purely automated RAG systems rely on:
- Similarity metrics (cosine similarity, vector distance)
- Heuristic ranking rules
These signals are insufficient in many real-world scenarios:
- Multiple retrieved documents may be technically relevant but practically useless
- Metrics do not capture user satisfaction or task correctness
- Domain nuance is often missed by embeddings
Adaptive RAG addresses this by incorporating expert human judgment directly into the pipeline.
Human Feedback as a System Signal
Human feedback is treated as structured data, not ad hoc comments.
Feedback can be applied to:
- Retrieved documents (relevance, usefulness)
- Generated answers (correctness, clarity)
- End-to-end task success
Integration Points in the RAG Pipeline
- Retriever level: Feedback adjusts document ranking or filtering, improving future retrieval results.
- Generator level: Feedback refines prompt construction or output constraints.
- Training level: Feedback data can be stored for later fine-tuning or reinforcement-style updates.
This creates a closed-loop system.
Adaptive Ranking and Re-Ranking
A key technical mechanism introduced is feedback-aware re-ranking.
Instead of ranking documents solely by similarity score:
- Similarity metrics provide an initial candidate set
- Human feedback scores influence final ranking
- Poorly performing documents are deprioritized even if semantically similar
Relationship to RLHF
Adaptive RAG borrows concepts from Reinforcement Learning from Human Feedback (RLHF) but applies them at the retrieval layer, not only at the model-training layer.
Differences:
- RLHF modifies model weights
- Adaptive RAG modifies retrieval behavior and context selection
Both approaches are complementary and can coexist.
Data Management Considerations
- Feedback must be stored with metadata (query, retrieved docs, timestamps)
- Feedback quality depends on expert selection
- Noise and inconsistency must be managed
Benefits of Adaptive RAG
- Improved retrieval precision over time
- Reduced hallucination due to better grounding
- Faster adaptation to domain changes without retraining
- It shifts improvement effort from model retraining to system-level learning.
Knowledge-Graph-Based RAG
Extending vector-based retrieval with explicit graph structures to improve precision, explain-ability, and multi-hop reasoning.
Motivation for Knowledge Graph RAG
Vector similarity search is effective for semantic matching but limited in scenarios that require:
- Explicit relationships between entities
- Structured reasoning across multiple facts
- Traceable and explainable retrieval paths
Knowledge graphs address these gaps by modeling data as nodes and edges, making relationships first-class citizens.
Data Collection and Graph Construction
Let’s use the Wikipedia API as a data source and follows a three-stage pipeline:
- Data collection
- Fetch structured and semi-structured content from Wikipedia
- Extract entities and relationships
- Vector storage
- Store text embeddings in a vector store (Deep Lake)
- Preserve links between embeddings and graph nodes
- Knowledge graph creation
- Build a graph where nodes represent entities
- Edges represent semantic or factual relationships
This creates a hybrid representation combining unstructured text and structured relationships.
Knowledge Graph Indexing with LlamaIndex
LlamaIndex is used to:
- Build a knowledge graph index
- Map retrieved vectors to graph nodes
- Enable graph-aware retrieval strategies
Instead of retrieving isolated text chunks, the system retrieves connected subgraphs relevant to the query.
Query-Time Retrieval Flow
At query time:
- The user query is embedded
- Initial candidates are retrieved via vector similarity
- Related nodes are expanded through graph traversal
- A connected context set is assembled
- The context is injected into the prompt for generation
This enables multi-hop retrieval, where answers depend on relationships rather than single documents.
Advantages Over Pure Vector RAG
Knowledge-graph-based RAG provides:
- Higher precision for fact-based queries
- Better handling of entity relationships
- Improved explainability through graph paths
- Reduced redundancy in retrieved context
It is particularly effective for domains with well-defined ontologies or entity relationships.
Limitations and Trade-Offs
- Graph construction and maintenance cost
- Dependency on accurate entity extraction
- Increased system complexity
- Not suitable for all data types or use cases
Knowledge graphs complement vector search. They do not replace it.
Dynamic RAG
A retrieval pattern designed for temporary, task-scoped knowledge rather than long-lived enterprise memory. Let’s focus on using Chroma as an ephemeral vector store and Hugging Face Llama models for generation.
Motivation for Dynamic RAG
Not all RAG use cases require persistent knowledge bases. Many scenarios involve:
- Short-lived meetings or workshops
- Task-specific context (daily reports, ad hoc analysis)
- Data that becomes irrelevant after a short time window
Persisting such data increases storage cost and governance complexity without long-term value.
Dynamic RAG addresses this by creating temporary vector collections that exist only for the duration of a task or session.
Ephemeral Vector Stores with Chroma
Chroma is used as a lightweight, local vector database that supports:
- Fast vector ingestion
- In-memory or short-lived persistence
- Rapid creation and deletion of collections
Each task or meeting can generate its own vector collection, avoiding contamination of long-term knowledge stores.
Data Ingestion and Embedding Flow
- Collecting task-specific documents
- Chunking and embedding content
- Inserting embeddings into a temporary Chroma collection
This process is automated and repeated frequently, often on a daily basis.
Query-Time Retrieval
At query time:
- The user query is embedded
- Similarity search is executed against the temporary collection
- Retrieved context is injected into the prompt
- The LLM generates a response grounded only in task-relevant data
Generation with Hugging Face Llama
Let’s use Hugging Face Llama models to demonstrate that Dynamic RAG is model-agnostic.
- Consumes augmented prompts
- Produces task-scoped outputs
- Does not retain long-term memory of retrieved data
This separation reinforces RAG as an external memory system.
Benefits of Dynamic RAG
- Reduced storage and indexing overhead
- Lower governance and compliance risk
- Faster setup for short-lived tasks
- Clear isolation between contexts
- It is particularly suited for meeting assistants, daily briefings, and temporary decision-support systems.
Limitations
Dynamic RAG is not suitable for:
- Long-term enterprise knowledge bases
- Cross-session learning
- Historical trend analysis
Scaling RAG
Focusing on large-volume vector ingestion, retrieval performance, and recommendation generation.
A common enterprise scenario:
- Large, structured and semi-structured customer datasets
- High query volume
- Need for fast, low-latency retrieval
- Requirement for explainable recommendations
Key Scaling Considerations
- Customer data representation: Structured and semi-structured attributes are transformed into meaningful text before embedding. Poor representation leads to low-quality similarity, regardless of model choice.
- Vector storage with metadata: Embeddings are stored alongside metadata such as customer segments or identifiers. Metadata filtering is essential to constrain retrieval and reduce noise.
- Retrieval performance control: Similarity search is combined with metadata filters and tuned top-K selection to maintain stable latency and cost at scale.
- Grounded generation: The LLM generates insights based on retrieved customer profiles, ensuring outputs are traceable to real data rather than generic patterns.
- Practical limits: RAG provides contextual grounding and explain-ability, not causal prediction. Human validation remains necessary for business decisions.
Fine-Tuning RAG Data and Human Feedback
Showing how selected non-parametric RAG data and human feedback can be converted into parametric knowledge to improve efficiency, cost, and response consistency.
Motivation for Fine-Tuning in RAG
Pure RAG systems rely entirely on runtime retrieval, which can introduce:
- Higher latency due to repeated retrieval
- Increased token usage from large context injection
- Redundant retrieval for frequently accessed knowledge
Fine-tuning is introduced as a way to compress stable, high-value knowledge into model weights while keeping RAG for dynamic data.
The decision to fine-tune depends on:
- Data stability
- Retrieval frequency
- Cost trade-offs between inference and storage
Fine-tuning is not a replacement for RAG. It is a selective optimization.
Risks and Constraints
The chapter highlights important limitations:
- Fine-tuning increases operational complexity
- Poor data quality degrades model behavior
- Over-fine-tuning reduces adaptability
- Retraining is required to update parametric knowledge
Fine-tuning should be applied incrementally and selectively.
Agentic-RAG
Standard Retrieval-Augmented Generation (RAG) architectures treat retrieval as a mostly passive step. A query is embedded, similar chunks are retrieved, and the LLM generates an answer from that context. This works well for simple queries, but breaks down when questions are ambiguous, multi-part, or require deep understanding of structured documents.
Agentic RAG introduces autonomous agents into the retrieval pipeline to actively reason about how retrieval should happen, not just what to retrieve.
Limitations of Conventional RAG
- Embeddings lose structure when documents contain tables or nested logic
- Queries are often underspecified or ambiguous
- Vector similarity alone retrieves semantically close but practically irrelevant chunks
- Retrieved context is noisy, duplicated, or poorly ordered
These are retrieval problems, not generation problems.
Agentic RAG Architecture Overview
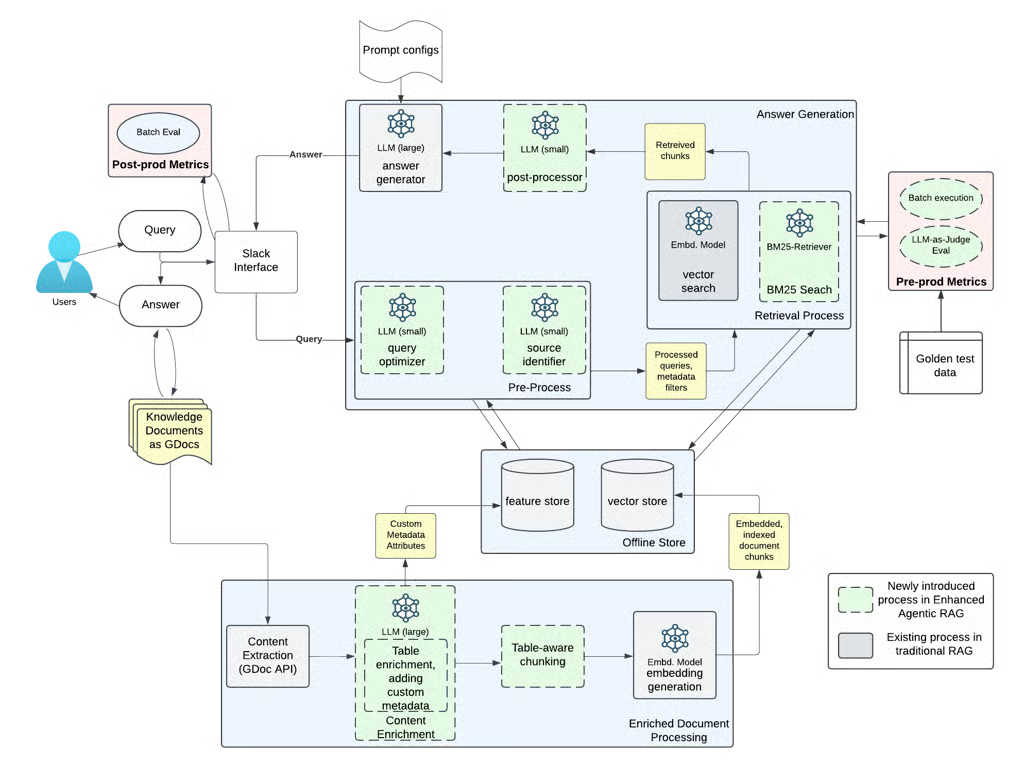
Agentic RAG decomposes retrieval into agent-driven stages, where each stage performs a specific reasoning task before or after retrieval.
Instead of a single retrieval call, the pipeline becomes an orchestrated workflow.
Agent Roles in the Retrieval Pipeline
Query Understanding Agent
This agent analyzes the incoming query and performs:
- Query rewriting
- Query expansion
- Decomposition into sub-queries
The goal is to reduce ambiguity and make retrieval intent explicit.
Source Selection Agent
Rather than searching the entire corpus, this agent narrows the retrieval scope using document-level signals such as summaries, keywords, or inferred relevance. This reduces noise and improves recall quality.
Hybrid Retrieval Strategy
Agentic RAG combines:
- Semantic retrieval (vector similarity)
- Lexical retrieval (keyword or sparse search)
The agent decides how to blend these signals, avoiding over-reliance on embeddings alone.
Context Post-Processing Agent
After retrieval, this agent:
- Removes redundant chunks
- Orders context logically
- Preserves document structure
This step is critical. LLMs perform better when context is coherent and well-structured.
Generation with Structured Context
Only after agent-driven refinement does the system invoke the LLM for generation. At this stage:
- The query is clearer
- The context is cleaner
- The grounding is stronger
The generator remains unchanged. Improvements come entirely from better retrieval orchestration.
Why Agentic RAG Matters
Enhanced Agentic RAG reframes RAG as a reasoning system, not a lookup mechanism.
Key shifts include:
- Retrieval becomes adaptive and goal-driven
- Agents encode heuristics that embeddings cannot
- Context quality improves without retraining models
- System accuracy improves through orchestration, not scale
This pattern is especially effective for:
- Complex policy or technical domains
- Structured or semi-structured documents
- Queries requiring interpretation rather than fact lookup
Components and processes of advanced RAG systems for enterprises
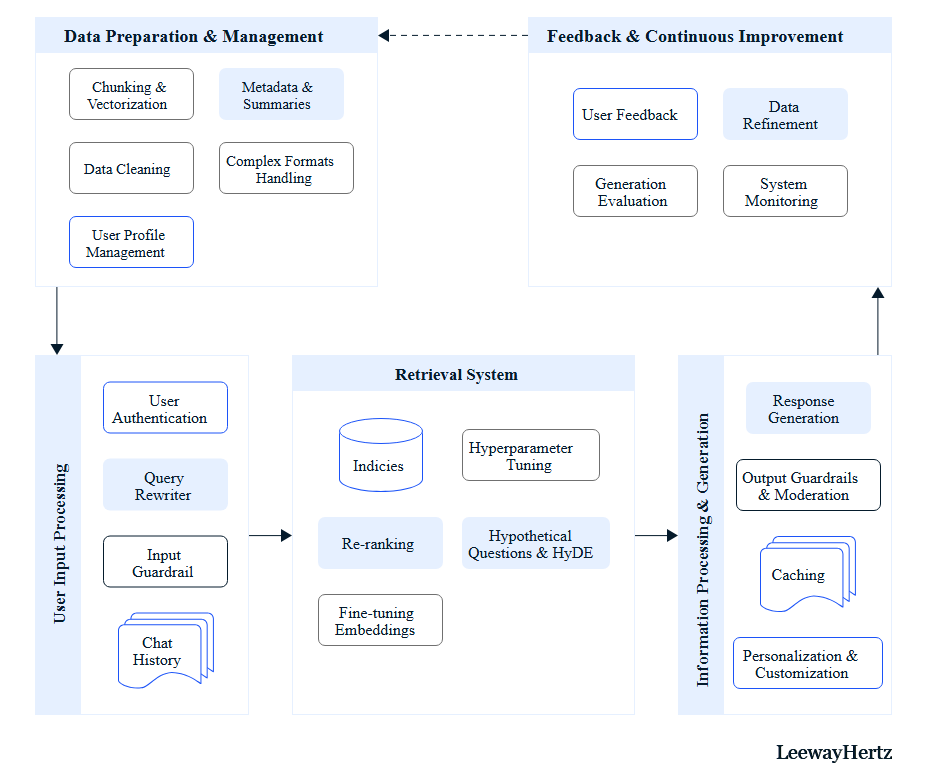
Advanced RAG techniques
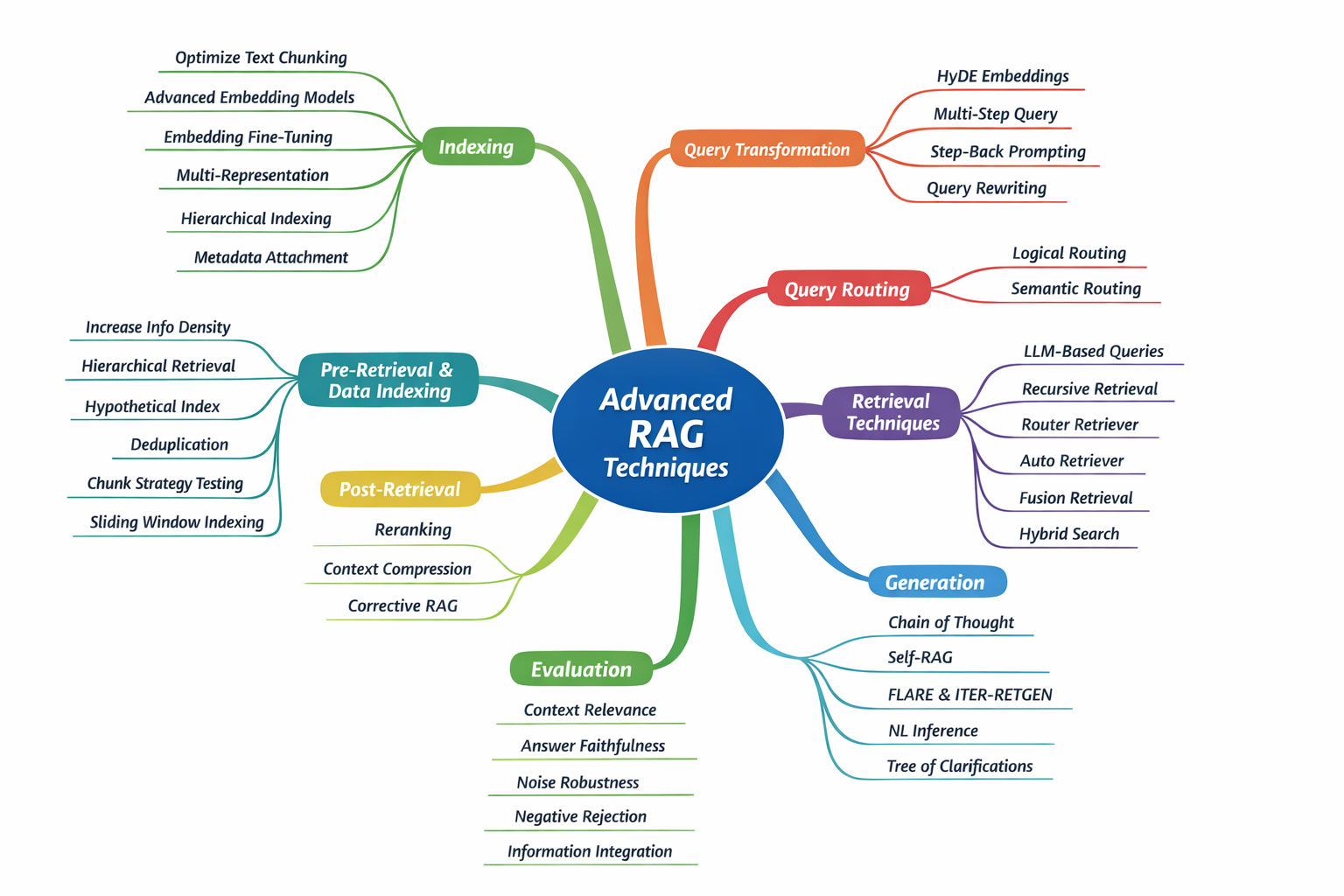
- Indexing
Technique 1: Optimize text chunking with chunk optimization
Technique 2: Transform texts into vectors with advanced embedding models
Technique 3: Enhance semantic matching with embedding fine-tuning
Technique 4: Improve retrieval efficiency with multi-representation
Technique 5: Organize data with hierarchical indexing
Technique 6: Enhance data retrieval with metadata attachment - Query transformation
Technique 1: Improve query clarity with HyDE (Hypothetical Document Embeddings)
Technique 2: Simplify complex queries with multi-step query
Technique 3: Enhance context with step-back prompting
Technique 4: Improve retrieval with query rewriting - Query routing
Technique 1: Direct queries with logical routing
Technique 2: Guide queries with semantic routing - Pre-retrieval and data-indexing techniques
Technique 1: Increase information density using LLMs
Technique 2: Apply hierarchical index retrieval
Technique 3: Improve retrieval symmetry with a hypothetical question index
Technique 4: Deduplicate information in your data index using LLMs
Technique 5: Test and optimize your chunking strategy
Technique 6: Use sliding window indexing for context preservation
Technique 7: Enhance data granularity with cleaning
Technique 8: Add metadata for precise filtering
Technique 9: Optimize index structure for richer retrieval - Retrieval techniques
Technique 1: Optimize search queries using LLMs
Technique 2: Fix query-document asymmetry with Hypothetical Document Embeddings (HyDE)
Technique 3: Implement query routing or a RAG decider pattern
Technique 4: Perform deep data exploration with recursive retriever
Technique 5: Optimize data source selection with router retriever
Technique 6: Automate query generation with auto retriever
Technique 7: Combine results for comprehensive retrieval with fusion retriever
Technique 8: Aggregate data contexts with auto merging retriever
Technique 9: Fine-tune embedding models for domain specificity
Technique 10: Implement dynamic embedding for contextual understanding
Technique 11: Leverage hybrid search for enhanced retrieval - Post-retrieval techniques
Technique 1: Prioritize search results with reranking
Technique 2: Optimize search results with contextual prompt compression
Technique 3: Score and filter retrieved documents with corrective RAG - Generation techniques
Technique 1: Tune out noise with Chain-of-Thought prompting
Technique 2: Make your system self-reflective with self-RAG
Technique 3: Ignore irrelevant context through fine-tuning
Technique 4: Use natural language inference to make LLMs robust against irrelevant context
Technique 5: Control data retrieval with FLARE
Technique 6: Refine responses with ITER-RETGEN
Technique 7: Clarify questions with ToC (Tree of Clarifications) - Evaluation
Context relevance
Answer faithfulness
Answer relevance
Noise robustness
Negative rejection
Information integration
Counterfactual robustness
