This is my learning note from the book Designing Cloud Data Platforms written by Danil Zburivsky and Lynda Partner. Support the authors by buying the book from Designing Cloud Data Platforms – Manning Publications
Cloud data platforms and cloud data warehouses: The practical aspects
Imagine that we’ve been tasked with building a small reporting solution for our organization. The Marketing department in our organization has data from their email marketing campaigns that is stored in a relational database—let’s assume it’s a MySQL RDBMS for this scenario. They also have clickstream data that captures all website user activity that is then stored in a CSV file that is available to us via an internal SFTP server.
We will use Azure as our cloud platform of choice for these examples. Azure Synapse is a fully managed and scalable warehousing solution from Microsoft, based on a very popular MS SQL Server database engine.
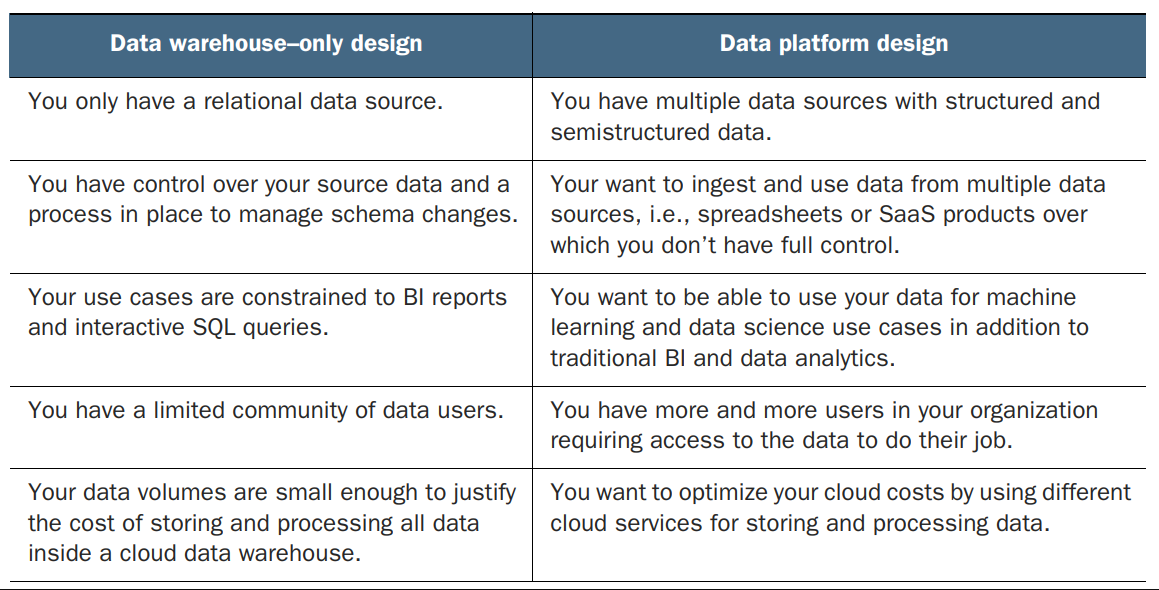
An example cloud data warehouse–only architecture
A cloud data warehouse architecture is quite similar to a traditional enterprise data warehouse solution. Below figure shows how the center of this architecture is a relational data warehouse that is responsible for storing, processing, and serving data to the end users. There is also an extract, transform, load (ETL) process that loads the data from the sources (clickstream data via CSV files and email campaign data from a MySQL database) into the warehouse.
Our example cloud data warehouse–only architecture consists of two PaaS services running on Azure: Azure Data Factory and Azure SQL Data Warehouse (Azure Synapse)
Azure Data Factory is a fully managed PaaS ETL service that allows you to create pipelines by connecting to various data sources, ingesting data, performing basic transformations such as uncompressing files or changing file formats, and loading data into a target system for processing and serving. We will also use Data Factory to load data into Azure Synapse.
Our example warehouse, Azure Synapse, is a fully managed warehouse service based on MS SQL Server technology. Fully managed in this case means that you don’t need to install, configure, and manage the database server yourself. Instead, you need only choose how much computational and storage capacity you require, and Azure will take care of the rest.
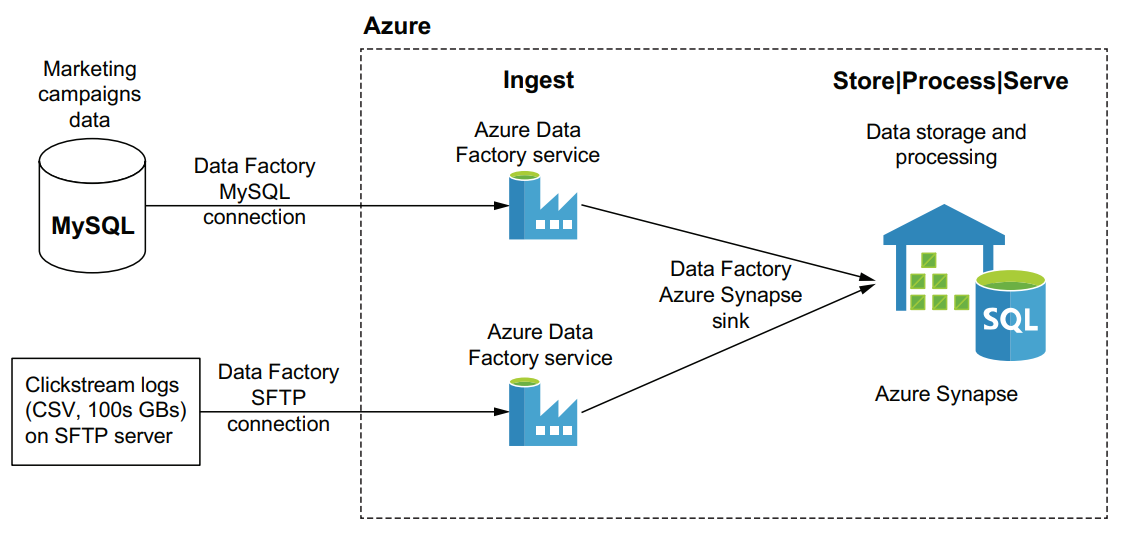
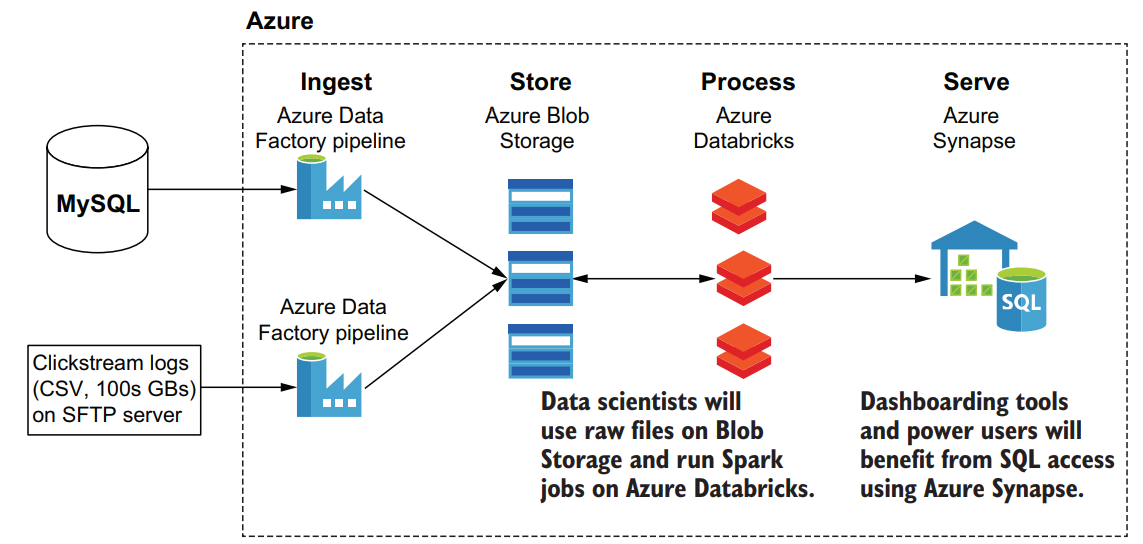
An example cloud data platform architecture
Our cloud data platform architecture consists of these Azure PaaS services:
- Azure Data Factory
- Azure Blob Storage
- Azure Synapse
- Azure Databricks
In the cloud data platform, while we are using Azure Data Factory to connect and extract data from the source systems instead of loading it directly into the warehouse, we will save the source data into a landing area on Azure Blob storage (often known as “the lake”). This allows us to preserve the original data format and helps with data variety challenges as well as provides other benefits.
Once the data has landed in Azure Blob Storage, we’ll use Apache Spark running on the Azure Databricks managed service (PaaS) to process it. As with all PaaS services, we get simple setup and ongoing management, allowing us to create new Spark clusters without needing to manually install and configure any software. It also provides an easy-to-use notebook environment where you can execute Spark commands against the data in the lake and see the results right away, without having to compile and submit Spark programs to the cluster.
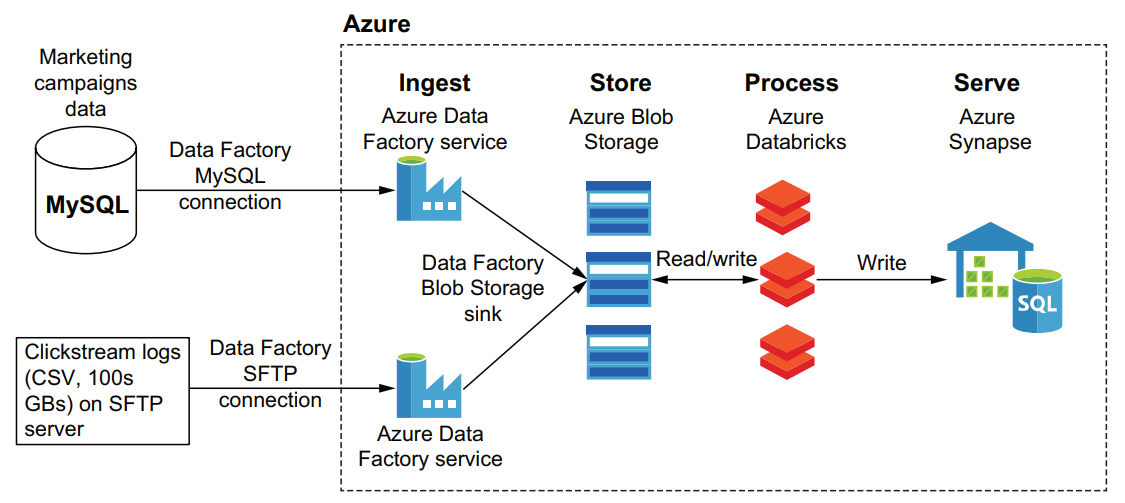
Ingesting data directly into Azure Synapse
Ingesting data into an Azure data platform
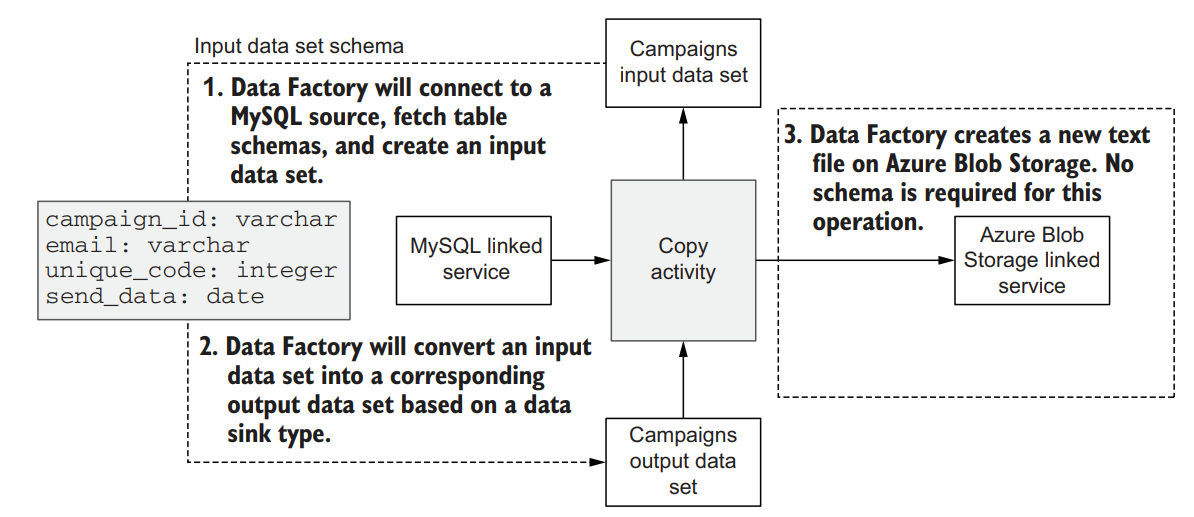
The main difference between this ingestion pipeline and the previous one is that Azure Blob Storage Data Factory service doesn’t require a schema to be specified up front. In our use case, each ingestion from MySQL is saved as a text file in Azure Blob Storage without concern for the source columns and data types. Our cloud data platform design has an extra layer of processing data, which will be implemented using Apache Spark running on the Azure Databricks platform to convert source text files into more efficient binary formats. This way we can combine the flexibility of text files on Azure Blob Storage with the efficiency of binary formats.
Processing data in the warehouse
This SQL suffers from an issue that is common to any SQL-based pipeline—the difficulty of testing it
Another challenge with running this type of SQL on Azure Synapse is that you can’t really use a number of performance optimizations that make Azure Synapse a great warehouse. Azure Synapse uses a columnar storage that allows columns that usually contain numbers or short text to be compressed and require less reads from disk while running a query. With JSON values you lose this optimization because you never work with a document as a whole, but rather need to parse it and access individual attributes.
Processing data in the data platform
Cloud offers multiple ways to process data at any scale outside of the data warehouse using a number of distributed data processing engines. Apache Spark is one of the most popular and widely adopted distributed data processing engines. All cloud vendors offer some sort of a managed service to run Spark jobs without having to worry about cluster deployment and configuration. Azure offers a managed environment for Spark that is based on Databricks (https://databricks.com/)—a commercial offering from the team that created Apache Spark.
Accessing data
This new data set might be of interest in different ways to different users inside your organization. For example:
- Marketing team—Often business users who want to consume the data in a dashboard that lists the top 10 pages visited for each campaign
- Data analyst—A power user, who may need to slice and dice data in multiple different ways
- Data scientist—An uber power user who may need to categorize users into different profiles based on pages visited
Cloud cost considerations
While Azure Synapse can be scaled up and down in terms of processing capacity using the Azure API, scaling takes time (tens of minutes sometimes) and during that time, the entire warehouse is unavailable. So does Azure Synapse support truly elastic scaling? Not exactly. Scaling Azure Synapse is something you can schedule to do every night if your users don’t require 24/7 access to the data, but it is not something you would be able to do multiple times a day, because that would be very disruptive. Another challenge is that you can’t create multiple instances of Azure Synapse that can work with the same data without having to copy data from one instance to another, which would take time as well.
In our cloud data platform design, we have Azure Blob Storage as our primary storage, and we use Spark running on Azure Databricks to do the processing. Databricks will copy the data you need to process to the virtual machines running Spark and will store it in memory. This copy does add some overhead when launching new jobs, but the benefit is that you can create multiple Spark clusters working with the same data. Those clusters can be of different sizes for different processing needs and can be terminated when not used to save cost. From an elasticity perspective, Azure Databricks provides better cost control options than Azure Synapse. It’s not uncommon to see a dedicated cluster be provisioned just to run a heavy SparkSQL query and then be torn down.
Use cases for a data warehouse–only vs. a data platform