This is my learning note from the book Designing Cloud Data Platforms written by Danil Zburivsky and Lynda Partner. Support the authors by buying the book from Designing Cloud Data Platforms – Manning Publications
Data warehouses struggle with data variety, volume, and velocity
Variety
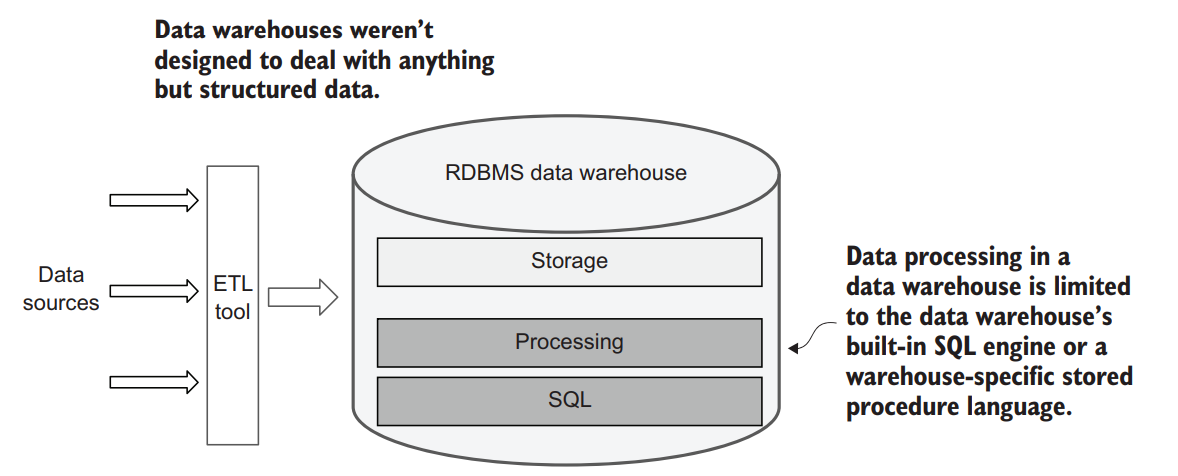
Variety is indeed the spice of life when it comes to analytics. But traditional data warehouses are designed to work exclusively with structured data. This worked well when most ingested data came from other relational data systems, but with the explosion of SaaS, social media, and IoT (Internet of Things), the types of data being demanded by modern analytics are much more varied and now includes unstructured data such as text, audio, and video.
Inside a data warehouse, you’re also limited to processing data either in the data warehouse’s built-in SQL engine or a warehouse-specific stored procedure language. This limits your ability to extend the warehouse to support new data formats or
processing scenarios. SQL is a great query language, but it’s not a great programming language because it lacks many of the tools today’s software developers take for granted: testing, abstractions, packaging, libraries for common logic, and so on.
Volume
Data volume is everyone’s problem. In today’s internet-enabled world, even a small organization may need to process and analyze terabytes of data. IT departments are regularly being asked to corral more and more data.
In a traditional data warehouse, storage and processing are coupled together, significantly limiting scalability and flexibility. To accommodate a surge in data volume in traditional relational data warehouses, bigger servers with more disk, RAM, and CPU to process the data must be purchased and installed. This approach is slow and very expensive, because you can’t get storage without compute, and buying more servers to increase storage means that you are likely paying for compute that you might not need, or vice versa.
Velocity
Traditional data warehouses are batch-oriented: take nightly data, load it into a staging area, apply business logic, and load your fact and dimension tables. This means that your data and analytics are delayed until these processes are completed for all new data in a batch. Streaming data is available more quickly but forces you to deal with each data point separately as it comes in. This doesn’t work in a data warehouse and requires a whole new infrastructure to deliver data over the network, buffer it in memory, provide reliability of computation, etc.
Data lakes to the rescue?
A data lake, as defined by TechTarget’s WhatIs.com is “A storage repository that holds a vast amount of raw data in its native format until it is needed.” Gartner Research adds a bit more context in its definition: “A collection of storage instances of various data assets additional to the originating data sources. These assets are stored in a near-exact (or even exact) copy of the source format. As a result, the data lake is an unintegrated, non-subject-oriented collection of data.”
After the introduction of Apache Hadoop in 2006, data lakes became synonymous with the ecosystem of open source software utilities, known simply as “Hadoop,” that provided a software framework for distributed storage and processing of big data using a network of many computers to solve problems involving massive amounts of data and computation. While most would argue that Hadoop is more than a data lake, it did address some
of the variety, velocity, and volume challenges discussed earlier in this chapter:
Variety—Hadoop’s ability to do schema on read (versus the data warehouse’s schema on write) meant that any file in any format could be immediately stored on the system, and processing could take place later. Unlike data warehouses, where processing could only be done on the structured data in the data warehouse, processing in Hadoop could be done on any data type.
Volume—Unlike the expensive, specialized hardware often required for warehouses, Hadoop systems took advantage of distributed processing and storage across less expensive commodity hardware that could be added in smaller increments as needed. This made storage less expensive, and the distributed nature of processing made it easier and faster to do processing because the workload could be split among many servers.
Velocity—When it came to streaming and real-time processing, ingesting and storing streaming data was easy and inexpensive on Hadoop. It was also possible, with the help of some custom code, to do real-time processing on Hadoop using products such as Hive or MapReduce or, more recently, Spark.
Building blocks of a cloud data platform
The purpose of a data platform is to ingest, store, process, and make data available for analysis no matter which type of data comes in—and in the most cost-efficient manner possible.
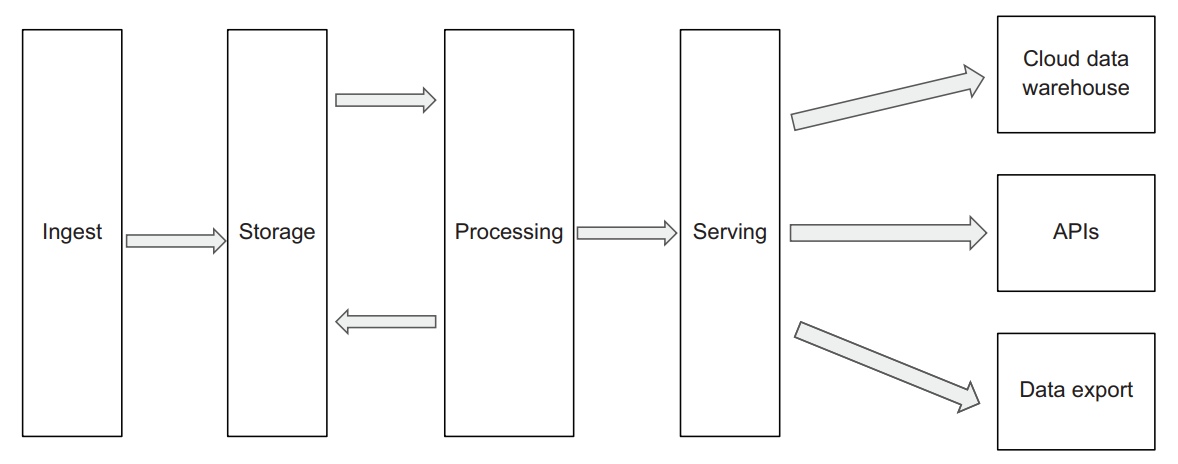
Ingestion layer
The ingestion layer is all about getting data into the data platform. It’s responsible for reaching out to various data sources such as relational or NoSQL databases, file storage, or internal or third-party APIs, and extracting data from them.
One of the most important characteristics of a data platform’s ingestion layer is that this layer should not modify and transform incoming data in any way. This is to make sure that the raw, unprocessed data is always available in the lake for data lineage tracking and reprocessing.
Storage layer
Once we’ve acquired the data from the source, it must be stored. This is where data lake storage comes into play. An important characteristic of a data lake storage system is that it must be scalable and inexpensive, so as to accommodate the vast amounts and velocity of data being produced today. The scalability requirement is also driven by the need to store all incoming data in its raw format, as well as the results of different data transformations or experiments that data lake users apply to the data.
Processing layer
After data has been saved to cloud storage in its original form, it can now be processed to make it more useful. The processing of data is arguably the most interesting part of building a data lake.
There are several technologies and frameworks available for implementing a processing layer in the cloud data lake, unlike traditional data warehouses, which typically
limited you to a SQL engine provided by your database vendor. However, while SQL is a great query language, it is not a particularly robust programming language. For example, it’s difficult to extract common data-cleaning steps into a separate, reusable library in pure SQL, simply because it lacks many of the abstraction and modularity features of modern programming languages such as Java, Scala, or Python. SQL also doesn’t support unit or integration testing. It’s very difficult to make iterative data transformations or data-cleaning code without good test coverage. Despite these limitations, SQL is still widely used in data lakes for analyzing data, and in fact many of the data service components provide a SQL interface.
Several data processing frameworks have been developed that combine scalability with support for modern programming languages and integrate well into the overall cloud paradigm. Most notable among these are:
- Apache Spark
- Apache Beam
- Apache Flink
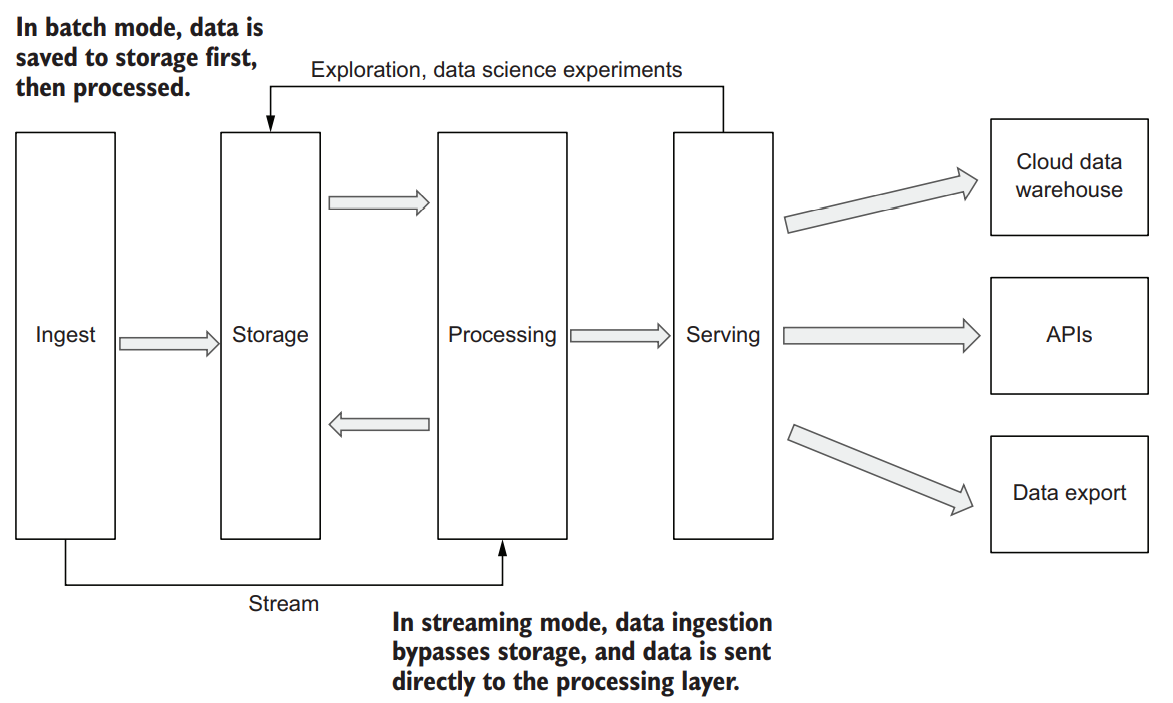
It’s also important, when thinking about data processing in the data lake, to keep in mind the distinction between batch and stream processing.
Serving layer
The goal of the serving layer is to prepare data for consumption by end users, be they people or other systems.
Business users often want access to reports and dashboards with rich self-service capabilities. The popularity of this use case is such that when we talk about data platforms, we almost always design them to include a data warehouse.
Power users and analysts want to run ad hoc SQL queries and get responses in seconds. Data scientists and developers want to use the programming languages they’re most comfortable with to prototype new data transformations or build machine learning models and share the results with other team members. Ultimately, you’ll typically have to use different, specialized technologies for different access tasks. But the good news is that the cloud makes it easy for them to coexist in a single architecture. For example, for fast SQL access, you can load data from the lake into a cloud data warehouse.
To provide data lake access to other applications, you can load data from the lake into a fast key/value or document store and point the application to that. And for data science and engineering teams, a cloud data lake provides an environment where they can work with the data directly in cloud storage by using a processing framework such as Spark, Beam, or Flink. Some cloud vendors also support managed notebook environments such as Jupyter Notebook or Apache Zeppelin. Teams can use these notebooks to build a collaborative environment where they can share the results of their experiments along with performing code reviews and other activities.
Two more V’s
Veracity and value are two other V’s that should factor into your choice of a data platform over just a data warehouse. Turning data into value only happens when your data users, be they people, models, or other systems, get timely access to data and use it effectively.

One thought on “Cloud Data Platform: Chapter 1: Introducing the data platform”