This is my learning note from the book Designing Cloud Data Platforms written by Danil Zburivsky and Lynda Partner. Support the authors by buying the book from Designing Cloud Data Platforms – Manning Publications
In this chapter, we’ll focus on the ingestion layer.
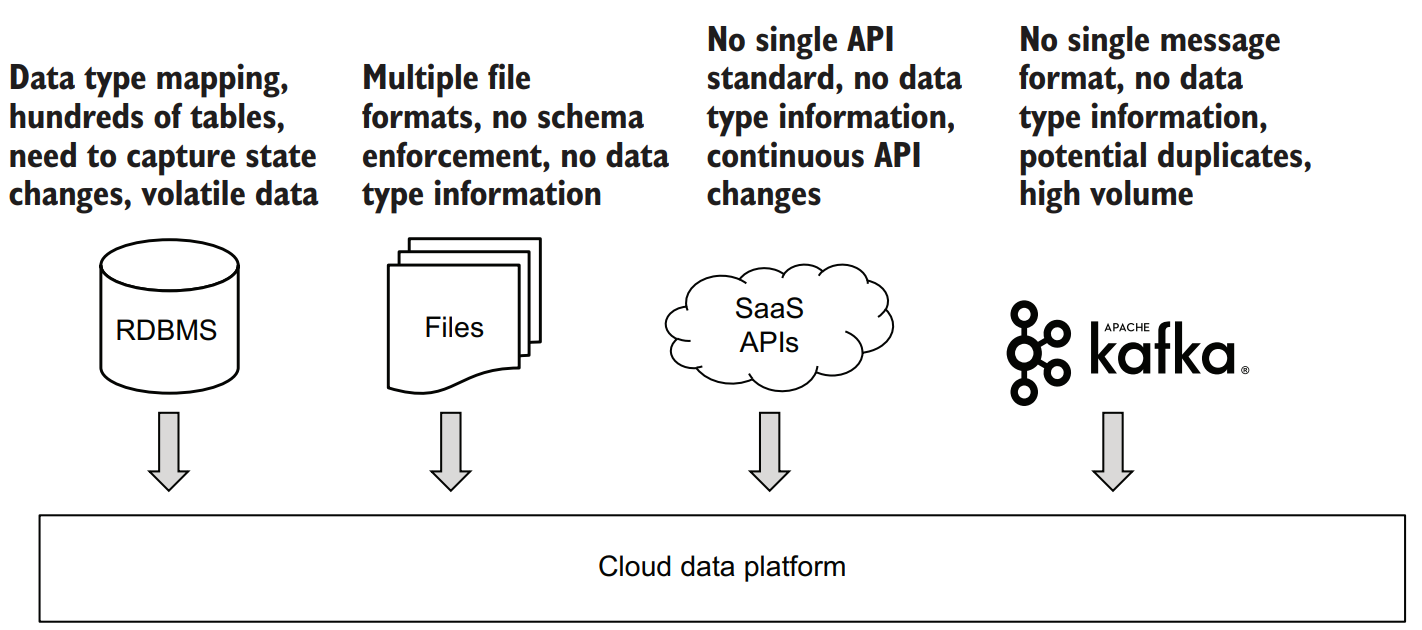
Databases, files, APIs, and streams
The complexity comes from the fact that a modern data platform must support ingestion from a variety of different data sources (remember the three V’s from chapter 1?), often at high velocities and in a consistent, uniform way. In this chapter, we will do an overview of the most common types of data sources we see today and provide some guidance on how to establish a robust ingestion process for each of them. We will specifically focus on databases (relational and NoSQL), files, APIs, and streams.
Relational databases
What do these RDBMS properties mean when it comes to implementing a data ingestion process into a common data platform? Here are some of the most important considerations
Mapping data types—Column data types from the source database must be mapped into the destination cloud warehouse. Unfortunately, each RDBMS and cloud vendor has their own set of supported data types. While many types overlap, such as strings, integers, and dates, there are always data types that are either unique to a particular vendor or behave differently in different databases. For example, TIMESTAMP types can have different precisions (microsecond, nanosecond, etc.), while DATE types can expect dates to be formatted a certain way, etc.
Automation—Since RDBMSs are often composed of hundreds of different tables, your ingestion process must be highly configurable and automated. No one will have time to manually configure ingestions for 600 different tables. Even if you have time to do it manually, you will most likely make mistakes along the way and end up with an ingestion process that is brittle and nonreproducible.
Volatility—Data in RDBMSs is typically highly volatile—businesses are never static and a lot of the business operations are captured in the database. For example, if you are dealing with a large e-commerce site, you will see hundreds or thousands of orders being placed, processed, edited, or cancelled every second. This in turn will result in data changes that affect dozens of tables. Your ingestion process must be able to deal with constantly changing data, capture data state at a given point in time, and deliver it into the data platform, where it can be processed and analyzed further.
Files
Here are some considerations when building a file-based ingestion process:
Parsing different file formats—You will need to parse different file formats: CSV, JSON, XML, Avro, etc. In the case of text file formats, there may be no guarantee that whoever produced the file followed the same conventions that your parser expects.
Dealing with schema changes—Unlike with RDBMSs, adding a new column to a CSV file or a new attribute to a JSON document is easy for data producers, and as such our experience shows that schema changes cases are very common in file-based data sources. Your ingestion process needs to be able to deal with this.
Snapshots and multiple files—As opposed to highly volatile RDBMS data, files usually represent a snapshot of some data set in time. A typical flow for a file-based data source is that data is extracted from some other system, saved as a text file, and then delivered to a destination. A single file can either represent a full snapshot of the source system (e.g., all orders) or a data increment (e.g., new orders since yesterday). Also any given ingestion batch can either be delivered as a single file or multiple files. Your ingestion process must take all of these options into account.
SaaS data via API
There are multiple challenges associated with using SaaS APIs. Each SaaS provider develops their own unique way of exposing data to external data consumers. For example, one provider may one have a single API endpoint that provides you with all the data you have in the system. Another provider may have an API endpoint for each object in their system, such as Customer, Contract, Vendor, etc. Some providers allow you to fetch data for a specified time frame, while others may either provide you with a full snapshot of data or only give you the last couple of days worth of data. This list goes on and on. This lack of standardization for data access and the resulting variety of API access methods makes ingesting data from SaaS into a data platform a challenging task. Here are some of the considerations you need to keep in mind when designing an ingestion process for SaaS:
If your organization uses multiple SaaS solutions, then you need to implement different data ingestion pipelines for each of those and constantly update them to keep up with the provider-introduced changes.
Very few SaaS provider APIs have any data type information available. From the perspective of data types, ingesting data from APIs is similar to dealing with JSON files—it’s up to the data pipeline implementation to do the necessary data type and schema validations.
There is also no standard for full versus incremental data load when it comes to SaaS APIs. You will need to adjust your pipeline for each provider.
Streams
Data streams usually represent events that happen at a given point in time.
The concept of event streams is not new, but several technological advances now make capturing and storing events scalable, reliable, and cost effective. Apache Kafka (an open source stream-processing software platform developed by LinkedIn, donated to Apache Software Foundation, and written in Scala and Java) is the most popular open source project created specifically for this purpose. Cloud-native streaming services are available from AWS (Kinesis), Google Cloud Pub/Sub, and Azure (Event Hubs) for integrating streaming data from cloud-native applications. Considerations for ingestion pipeline design are the same across both open source and cloud service options and include
In data streams systems, there is a message format restriction. All messages are stored as an array of bytes and can encode data as a JSON document, an Avro message, or any other format. Your ingestion pipeline must be able to decode the messages back into a consumable format.
To deliver data reliably and at scale, streaming data systems allow the same messages to be consumed multiple times. This means that the data ingestion pipeline must be able to deal efficiently with duplicate data.
Messages in streaming data systems are immutable. Once written by the producer, they cannot be changed, but a new version of the same message can be delivered later, so your data platform may need to be able to resolve multiple versions of the same message.
Streaming data is typically high-volume data. Your ingestion pipeline must be able to scale accordingly.
