Bài viết được dịch từ Pattern: Service Mesh by Phil Calçado
Kể từ lần giới thiệu đầu tiên cách đây nhiều thập kỷ, chúng ta đã biết rằng các hệ thống phân tán cho phép thiết kế các hệ thống theo cách chưa từng được nghĩ tới, nhưng chúng cũng mang lại nhiều vấn đề mới.
Khi hệ thống còn đơn giản, các kỹ sư đã giải quyết sự phức tạp gia tăng bằng cách giảm thiểu số lượng các tương tác từ xa (remote interactions). Cách an toàn nhất để xử lý phân tán là tránh nó càng nhiều càng tốt, ngay cả khi điều đó sẽ mang đến sự trùng lặp dữ liệu và logic trên các hệ thống khác nhau.
Nhưng nhu cầu của chúng ta với tư cách là một ngành công nghiệp đã thúc đẩy mình đi xa hơn thế, từ một vài máy tính trung tâm đến hàng trăm và hàng nghìn microservices. Chúng ta phải bắt đầu vượt ra khỏi giới hạn và giải quyết những thách thức mới và các câu hỏi mở, trước tiên là với các giải pháp đặc biệt được thực hiện theo từng trường hợp cụ thể và sau đó là các giải pháp phức tạp hơn. Khi tìm hiểu thêm về miền vấn đề và thiết kế các giải pháp tốt hơn, chúng ta bắt đầu kết tinh một số nhu cầu phổ biến nhất vào các pattern, library và cuối cùng là nền tảng framework.
Điều gì đã xảy ra khi kỷ nguyên mạng máy tính ban đầu
Vì lần đầu tiên mọi người nghĩ về việc có hai hoặc nhiều máy tính nói chuyện với nhau, họ đã hình dung ra một thứ như thế này:
Một service giao tiếp với một service khác để hoàn thành một số tác vụ cho người dùng. Đây rõ ràng là một cái nhìn đơn giản hóa quá mức, cần phải có network thì các máy tính mới nói chuyện được với nhau. Hãy chỉ thêm một chút chi tiết bằng cách hiển thị ngăn xếp mạng như một thành phần riêng biệt:
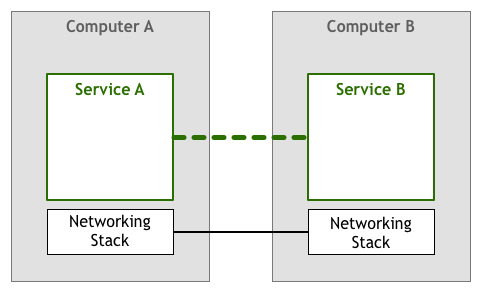
Các biến thể của mô hình trên đã được sử dụng từ những năm 1950. Vào thời kỳ đầu, máy tính rất hiếm và đắt tiền, vì vậy mỗi liên kết giữa hai node đều được thiết kế, thực thi và bảo trì cẩn thận. Khi máy tính trở nên rẻ hơn và phổ biến hơn, số lượng kết nối và lượng dữ liệu đi qua chúng tăng lên đáng kể. Với việc mọi người ngày càng phụ thuộc nhiều hơn vào các hệ thống kết nối mạng, các kỹ sư cần đảm bảo rằng phần mềm mà họ đã xây dựng phải đạt được chất lượng dịch vụ mà người dùng yêu cầu.
Và có rất nhiều câu hỏi cần được trả lời để đạt được mức chất lượng mong muốn. Con người cần tìm cách để các máy tính tìm thấy nhau, xử lý nhiều kết nối đồng thời, cho phép các máy giao tiếp với nhau khi không kết nối trực tiếp, định tuyến các gói mạng, mã hóa lưu lượng, v.v.
Trong số đó, có một thứ gọi là điều khiển luồng (flow control), mà chúng ta sẽ sử dụng làm ví dụ. Flow control là một cơ chế ngăn một máy chủ gửi nhiều request hơn mức mà máy chủ nhận có thể xử lý. Điều đó là cần thiết vì trong một hệ thống mạng, bạn có ít nhất hai máy tính riêng biệt, độc lập không biết nhiều về nhau. Máy tính A gửi các request với tốc độ nhất định đến Máy tính B, nhưng không có gì đảm bảo rằng B sẽ xử lý các request đã nhận với tốc độ nhất quán và đủ nhanh. Ví dụ: B có thể đang bận chạy các tác vụ khác song song hoặc các request có thể đến không theo thứ tự, và B sẽ chờ các request mà lẽ ra phải đến trước. Điều này có nghĩa là không chỉ A sẽ không có hiệu suất như mong đợi từ B mà còn có thể khiến mọi thứ trở nên tồi tệ hơn, vì nó có thể làm quá tải B.
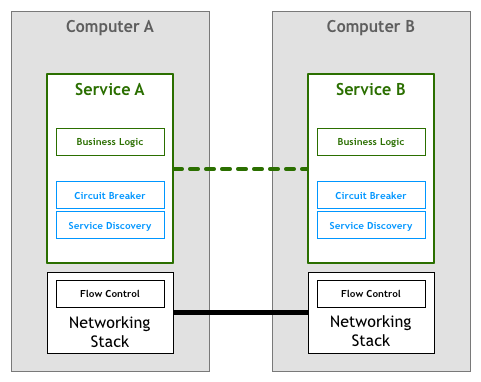
Sau một thời gian, người ta mong đợi rằng những người xây dựng các dịch vụ và ứng dụng mạng sẽ đối phó với những thách thức được trình bày ở trên trong đoạn mã mà họ đã viết. Trong ví dụ điều khiển luồng, điều đó có nghĩa là bản thân ứng dụng phải chứa logic để đảm bảo rằng chúng không làm quá tải một dịch vụ khác. Logic mạng được viết cùng với business logic. Như trong sơ đồ dưới đây:
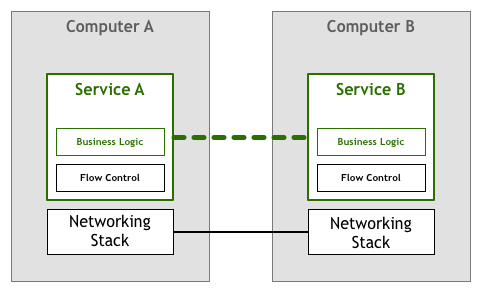
May mắn thay, công nghệ nhanh chóng phát triển và sớm có đủ các tiêu chuẩn như TCP/IP đã kết hợp các giải pháp để kiểm soát luồng và nhiều vấn đề khác vào hệ thống mạng. Điều này có nghĩa là đoạn mã đó vẫn tồn tại, nhưng nó đã được chuyển từ ứng dụng của bạn sang lớp mạng bên dưới do hệ điều hành cung cấp:
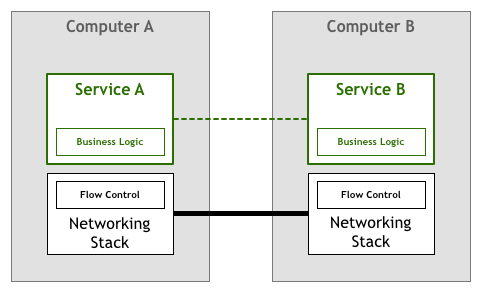
Mô hình này đã rất thành công. Các tổ chức bắt đầu sử dụng các lớp phương thức TCP/IP để thúc đẩy hoạt động kinh doanh, ngay cả khi hiệu suất và độ tin cậy cao cần được bảo đảm.
Điều gì đã xảy ra khi chúng ta lần đầu tiên bắt đầu với microservices
Trong những năm qua, máy tính thậm chí còn rẻ hơn và có mặt ở khắp mọi nơi, và các lớp phương thức mạng được mô tả ở trên đã tự chứng minh mình là bộ công cụ để kết nối các hệ thống một cách đáng tin cậy. Với nhiều node hơn và kết nối ổn định, từ đó sản sinh ra nhiều kiểu hệ thống mới, từ fine-grained distributed agents and objects đến Kiến trúc hướng dịch vụ (Service-Oriented Architectures) bao gồm các thành phần lớn hơn nhưng vẫn có tính chất phân tán.
Dạng kiến trúc này mang lại rất nhiều trường hợp sử dụng và lợi ích, nhưng nó cũng nảy sinh ra các thách thức. Một số thách thức trong số này là hoàn toàn mới, nhưng những thách thức khác chỉ là phiên bản cấp cao hơn của những thách thức mà chúng ta đã thảo luận khi nói về mạng thô sơ.
Vào những năm 90, Peter Deutsch và các kỹ sư đồng nghiệp của ông tại Sun Microsystems đã biên soạn “8 vấn đề của hệ thống phân tán”, trong đó ông liệt kê một số giả định mà mọi người có xu hướng đặt ra khi làm việc với các hệ thống phân tán. Quan điểm của Peter là những điều này, có thể đúng trong các kiến trúc mạng nguyên thủy hoặc các mô hình lý thuyết, nhưng chúng không đúng trong thế giới hiện đại, các giả định mà mọi người hay đặt ra là:
- Mạng phải đáng tin cậy (The network is reliable)
- Độ trễ phải bằng 0 (Latency is zero)
- Băng thông là vô hạn (Bandwidth is infinite)
- Mạng phải an toàn (The network is secure)
- Cấu trúc liên kết không thay đổi (Topology doesn’t change)
- Có một quản trị viên (There is one administrator)
- Chi phí vận chuyển bằng 0 (Transport cost is zero)
- Mạng phải đồng nhất (The network is homogeneous)
Việc từ chối đảm bảo những điều phía trên là chỉ là sự “ngụy biện”. Có nghĩa là các kỹ sư không thể bỏ qua những vấn đề này, họ phải giải quyết chúng một cách rõ ràng.
Để làm phức tạp thêm vấn đề, việc chuyển sang các hệ thống siêu phân tán – cái mà chúng ta thường gọi là kiến trúc microservices – đã sinh ra những nhu cầu mới về khía cạnh khả năng hoạt động. Chúng ta đã thảo luận chi tiết về một số vấn đề này trước đây, nhưng đây là danh sách nhanh về những gì người ta phải giải quyết:
- Cung cấp nhanh chóng các tài nguyên máy tính (Rapid provisioning of compute resources)
- Giám sát cơ bản (Basic monitoring)
- Triển khai nhanh chóng (Rapid deployment)
- Dễ dàng cung cấp kho lưu trữ (Easy to provision storage)
- Dễ dàng tiếp cận các edge (Easy access to the edge)
- Xác thực / Phân quyền (Authentication/Authorisation)
- RPC tiêu chuẩn hóa (Standardised RPC)
Vì vậy, trong khi mô hình mạng chung và TCP/IP được phát triển cách đây nhiều thập kỷ vẫn là một công cụ mạnh mẽ trong việc giúp cho các máy tính giao tiếp với nhau, thì các kiến trúc phức tạp hơn đã dẫn tới một lớp yêu cầu khác mà một lần nữa cần phải được giải quyết bởi chính các kỹ sư làm việc trong các kiến trúc như vậy.
Ví dụ, hãy xem xét service discovery và circuit breakers, hai kỹ thuật được sử dụng để giải quyết một số thách thức về khả năng phục hồi (resiliency) và phân tán được liệt kê ở trên.
Khi lịch sử có xu hướng lặp lại, các tổ chức đầu tiên xây dựng hệ thống dựa trên microservices đã tuân theo một chiến lược rất giống với chiến lược của một vài thế hệ máy tính mạng đầu tiên. Điều này có nghĩa là trách nhiệm giải quyết các yêu cầu được liệt kê ở trên được giao cho kỹ sư viết dịch vụ.
Service discovery là quá trình tự động tìm các bản sao của dịch vụ để thực hiện một request nhất định, ví dụ: một dịch vụ được gọi là Teams cần tìm các bản sao của một dịch vụ được gọi là Players với attribute environment được set với production. Bạn sẽ thực hiện các xử lý service discovery và trả về một danh sách các máy chủ phù hợp. Đối với các kiến trúc monolithic, đây là một tác vụ đơn giản thường được thực hiện bằng cách sử dụng DNS, bộ cân bằng tải và một số quy ước về số cổng (ví dụ: tất cả các dịch vụ liên kết máy chủ HTTP của họ với cổng 8080). Trong các môi trường phân tán, công việc bắt đầu trở nên phức tạp hơn và các dịch vụ trước đây có thể tin tưởng một cách mù quáng vào việc tra cứu DNS để tìm các service khác thì giờ đây phải đối phó với những thứ như cân bằng tải phía máy khách, nhiều môi trường khác nhau (ví dụ: staging, production), máy chủ được phân phối theo địa lý, v.v. Nếu trước đây tất cả những gì bạn cần là một dòng mã để phân giải tên máy chủ, thì bây giờ các dịch vụ của bạn cần nhiều hơn thế để giải quyết các trường hợp khác nhau trong một hệ thống phân tán phức tạp.
Bộ ngắt mạch (circuit breakers) là một pattern được Michael Nygard nói đến trong cuốn Release It. Nhưng tôi thích bản tóm tắt của Martin Fowler cho pattern này:
Ý tưởng cơ bản đằng sau bộ ngắt mạch rất đơn giản. Bạn bọc một lệnh gọi hàm được bảo vệ trong một bộ ngắt mạch, bộ ngắt mạch này sẽ theo dõi các lỗi hỏng hóc. Khi sự cố đạt đến một ngưỡng nhất định, nó sẽ kích hoạt và tất cả các cuộc gọi tiếp theo đến bộ ngắt mạch đều quay trở lại với một lỗi mà không có cuộc gọi nào thực sự được thực hiện. Thông thường, bạn cũng sẽ muốn nhận được các cảnh báo nếu bộ ngắt mạch bị kích hoạt.
Đây là những cách đơn giản tuyệt vời để tăng thêm độ tin cậy cho các tương tác giữa các services. Tuy nhiên, cũng giống như mọi thứ khác, chúng có xu hướng trở nên phức tạp hơn khi mức độ phân tán tăng lên. Khả năng xảy ra sự cố trong hệ thống tăng lên theo cấp số nhân với sự phân tán, vì vậy ngay cả những thứ đơn giản như “cảnh báo nếu bộ ngắt mạch được kích hoạt” cũng không còn đơn giản nữa. Một lỗi trong một service có thể tạo ra một loạt các hiệu ứng lỗi dây chuyền trên nhiều services và services của services (cascading failure), kích hoạt hàng nghìn bộ ngắt mạch cùng một lúc. Một lần nữa, những gì trước đây chỉ là một vài dòng mã, giờ đây đòi hỏi vô số logic giống nhau (boilerplate) để xử lý các tình huống đang tồn tại trong thế giới mới này.
Trên thực tế, hai ví dụ được liệt kê ở trên có thể khó thực hiện chính xác đến mức các thư viện lớn, phức tạp như Finagle của Twitter và Proxygen của Facebook đã trở nên rất phổ biến như một phương tiện để tránh viết lại cùng một logic trong mọi service.
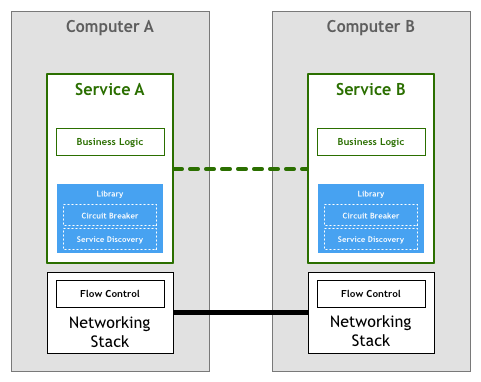
Diagram vừa nêu đã được đa số các tổ chức đi tiên phong trong kiến trúc microservices tuân theo, như Netflix, Twitter và SoundCloud. Khi số lượng dịch vụ trong hệ thống của họ tăng lên, họ cũng vấp phải những nhược điểm khác nhau của phương pháp này.
Có lẽ thách thức tốn kém nhất, ngay cả khi sử dụng một thư viện như Finagle, là một tổ chức vẫn sẽ cần đầu tư thời gian từ đội ngũ kỹ sư của mình trong việc xây dựng sự kết nối các thư viện với phần còn lại của hệ sinh thái của họ. Dựa trên kinh nghiệm của tôi tại SoundCloud và DigitalOcean ước tính rằng thực hiện theo chiến lược này trong một tổ chức 100-250 kỹ sư, một người sẽ cần dành 1/10 số kỹ sư chuyên trách cho việc xây dựng công cụ.
Vấn đề thứ hai là việc thiết lập các công cụ phải độc lập và không phụ vào runtimes và ngôn ngữ đang dùng trong các microservices. Các thư viện cho microservices thường được viết cho một ngôn ngữ lập trình hay nền tảng cụ thể, ví dụ như Java, JVM. Nếu một tổ chức sử dụng các nền tảng khác với nền tảng được thư viện hỗ trợ, nó thường cần chuyển mã sang nền tảng mới. Điều này một lần nữa, lại cần thời gian. Thay vì làm việc với sản phẩm cốt lõi của họ, các kỹ sư phải xây dựng các công cụ và cơ sở hạ tầng. Đó là lý do tại sao một số tổ chức quy mô vừa như SoundCloud và DigitalOcean quyết định chỉ hỗ trợ một nền tảng cho các dịch vụ nội bộ của họ — tương ứng là Scala và Go.
Một vấn đề cuối cùng của mô hình này đáng bàn là vấn đề quản trị. Mô hình thư viện có thể trừu tượng hóa việc triển khai các tính năng cần thiết để đáp ứng nhu cầu của kiến trúc microservices, nhưng bản thân nó vẫn là một thành phần cần được bảo trì. Đảm bảo rằng hàng nghìn phiên bản services đang sử dụng cùng một phiên bản hoặc ít nhất là tương thích với thư viện của bạn không phải là chuyện nhỏ. Khi có một bản bản cập nhật thì cần phải tích hợp, thử nghiệm và triển khai lại tất cả các services — ngay cả khi bản thân service đó không thay đổi gì.
Bước đi tiếp theo
Tương tự như những gì chúng ta đã thấy trước đó, việc trích xuất các tính năng được yêu cầu bởi các dịch vụ phân tán thành một nền tảng (platform) là điều cần được tiến hành.
Mọi người viết các ứng dụng và dịch vụ rất phức tạp bằng cách sử dụng các giao thức cấp cao hơn như HTTP mà không cần nghĩ đến cách giao thức TCP kiểm soát các gói tin trên network như thế nào. Tình huống này là những gì chúng ta cần đối với microservices, các kỹ sư làm việc trên các service có thể tập trung vào business logic và tránh lãng phí thời gian trong việc viết mã hay quản lý thư viện liên quan đến nền tảng cơ sở hạ tầng.
Với ý tưởng này, chúng ta có thể đi đến một cái gì đó như sau:
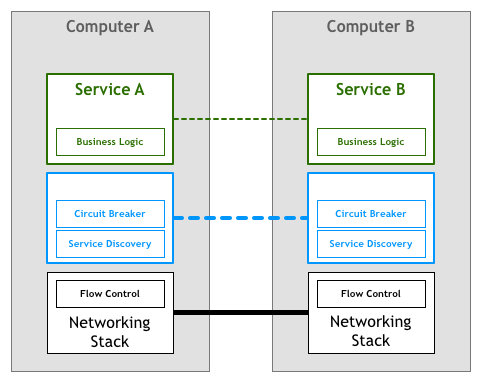
Thật không may, việc thay đổi ngăn xếp mạng để thêm lớp này không phải là một nhiệm vụ khả thi. Giải pháp được nhiều kỹ sư tìm ra là triển khai nó dưới dạng một tập hợp các proxy. Ý tưởng ở đây là một service sẽ không kết nối trực tiếp với các downstream dependencies, thay vào đó, tất cả truy cập sẽ đi qua một phần mềm nhỏ bổ sung các tính năng như đã nói ở trên.
Những triển khai được ghi nhận đầu tiên đã sử dụng khái niệm sidecar. Một sidecar là một process phụ trợ chạy song song với ứng dụng và cung cấp các tính năng bổ sung. Vào năm 2013, Airbnb đã nói về Synapse và Nerve – các triển khai của sidecar pattern dưới dạng nguồn mở (open-source). Một năm sau, Netflix đã giới thiệu Prana, một sidecar dành riêng cho việc cho phép các ứng dụng không phải JVM hưởng lợi từ hệ sinh thái NetflixOSS của họ. Tại SoundCloud, chúng tôi đã xây dựng các sidecar cho phép các ứng dụng Ruby sử dụng cơ sở hạ tầng đã xây dựng dành cho các JVM microservices.
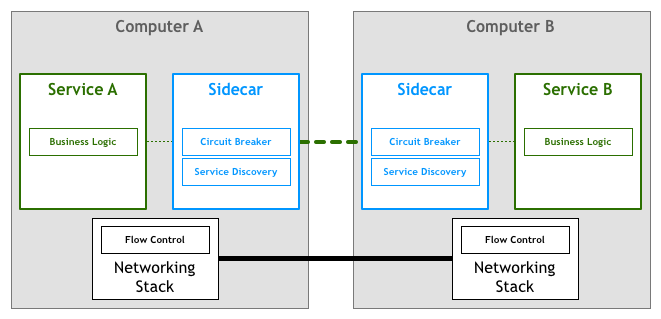
Mặc dù có một số triển khai proxy nguồn mở này, nhưng chúng có xu hướng được thiết kế để hoạt động với các thành phần cơ sở hạ tầng cụ thể. Ví dụ, nói đến service discovery, Nerve & Synapse của Airbnb yêu cầu các services được đăng ký trong Zookeeper, còn với Prana, các services cần sử dụng Eureka của Netflix.
Với sự phổ biến ngày càng tăng của kiến trúc microservices, gần đây chúng ta đã thấy một làn sóng proxy mới đủ linh hoạt để thích ứng với các thành phần và sở thích cơ sở hạ tầng khác nhau. Hệ thống đầu tiên được biết đến rộng rãi trên không gian này là Linkerd, do Buoyant tạo ra dựa trên công việc trước đây của các kỹ sư của họ trên nền tảng microservices của Twitter. Không lâu sau, nhóm kỹ sư tại Lyft đã công bố Envoy cũng theo một cơ chế tương tự.
Service Mesh
Trong mô hình như vậy, mỗi service sẽ có một sidecar đồng hành. Giả sử rằng các service chỉ giao tiếp với nhau thông qua sidecar, chúng ta sẽ có sơ đồ như bên dưới:
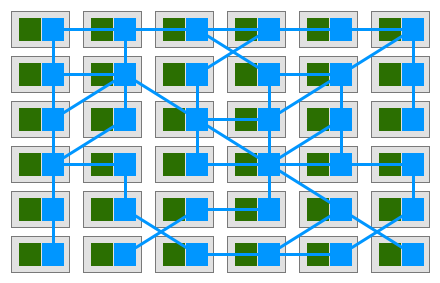
CEO của Buoyant là William Morgan đã quan sát và thấy rằng các kết nối giữa các sidecar tạo thành một mesh network. Vào đầu năm 2017, William đã viết một định nghĩa cho nền tảng này và gọi nó là Service Mesh:
Service Mesh là một lớp cơ sở hạ tầng chuyên dụng để xử lý giao tiếp giữa dịch vụ và dịch vụ. Nó chịu trách nhiệm cung cấp các yêu cầu đáng tin cậy thông qua cấu trúc liên kết phức tạp của các service theo kiến trúc hiện đại và cloud-native. Trong thực tế, Service Mesh thường được triển khai dưới dạng một loạt các sidecar proxy gọn nhẹ được triển khai cùng với ứng dụng mà bản thân ứng dụng không cần biết đến sidecar proxy.
Có lẽ khía cạnh đáng lưu ý nhất trong định nghĩa của ông là nó không nghĩ đến proxy như các thành phần biệt lập và thừa nhận mạng lưới mà chúng hình thành như một thứ gì đó có giá trị.
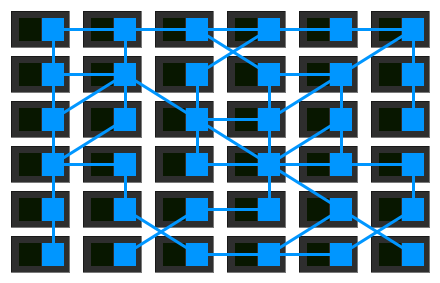
Khi các tổ chức chuyển việc triển khai microservices của họ sang các nền tảng phức tạp hơn như Kubernetes và Mesos, mọi người đã bắt đầu sử dụng các công cụ được cung cấp bởi các nền tảng đó để thực hiện ý tưởng về Service Mesh đúng cách. Họ đang chuyển từ một tập hợp các proxy độc lập hoạt động riêng lẻ sang dạng điều khiển tập trung được gọi là Control Plane.
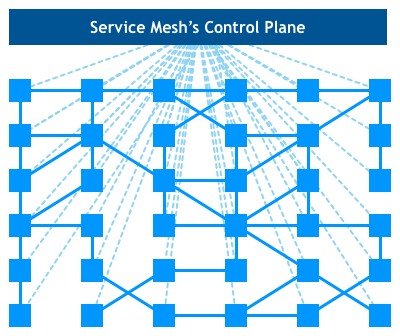
Nhìn vào hình, chúng ta thấy rằng các giao tiếp dịch vụ vẫn trực tiếp đi từ proxy này sang proxy khác, nhưng control plane biết về tất cả các proxy. Control plane cho phép proxy triển khai những thứ như kiểm soát truy cập và thu thập số liệu, đòi hỏi sự hợp tác giữa các proxy:
Các dự án Istio, Linkerd được công bố gần đây là ví dụ nổi bật nhất của hệ thống như vậy.
Vẫn còn quá sớm để hiểu đầy đủ về tác động của Service Mesh trong các hệ thống quy mô lớn. Tuy nhiên, tôi đã thấy rõ hai lợi ích của phương pháp này. Đầu tiên, việc không phải viết phần mềm tùy chỉnh để xử lý những vấn đề thường gặp trong kiến trúc microservices sẽ cho phép nhiều tổ chức nhỏ hơn tận hưởng các tính năng trước đây chỉ dành cho các doanh nghiệp lớn, tạo ra tất cả các trường hợp sử dụng thú vị. Điều thứ hai là kiến trúc này có thể cho phép chúng ta cuối cùng cũng hiện thực hóa giấc mơ sử dụng công cụ / ngôn ngữ tốt nhất cho công việc mà không cần lo lắng về tính sẵn có của các thư viện và patterns cho từng nền tảng.
Lời cảm ơn
Tới Monica Farrell, Rodrigo Kumpera, Etel Sverdlov, Dave Worth, Mauricio Linhares, Daniel Bryant, Fabio Kung, và Carlos Villela đã đưa ra các góp ý để hoàn thiện bài viết này.
Lịch sử sửa đổi
03/08/2017 – Lần đầu xuất bản
05/08/2017 – Chỉnh sửa dựa trên các góp ý
